1. Introduction
This is the first in a series on Deep Reinforcement Learning (DRL) inspired by recent kitchen counter side discussions with friends. A apt way to introduce the value and power of DRL is to contrast it with self-supervised pre-training in LLMs / DNNs. If we consider games such as chess, while it is possible to pre-train a model once on the rules of the game, by far and away the best way for it to become adept is by doing so empirically – in DRL this is effected by providing an environment where the model may play the game and learn optimal strategies in a phenomenological way. The environment is engineered to deliver a reward signal to the model during intermediate and/or end states of the game. To somewhat simplify the narrative – the magnitude of the reward signal may be then used to construct a loss function that is used to train the model through standard methods from non-convex optimization. The power of Deep RL has been evidenced not just in the area of games (AlpaZero, AlphaGo) and robotics, but also to enhance the reasoning capabilities of frontier LLMs for a number of tasks with automatically verifiable rewards such as math problems and coding. The power of this method is evidenced by a recent article in Nature on outcomes related DeepseekR1 with regards to DRL on Chain of Thought (Cot) fueled reasoning tasks – these outcomes are summed up by the following remark from the article – “The self-evolution of DeepSeek-R1-Zero underscores the power and beauty of RL: rather than explicitly teaching the model how to solve a problem, we simply provide it with the right incentives and it autonomously develops advanced problem-solving strategies. This serves as a reminder of the potential of RL to unlock higher levels of capabilities in LLMs, paving the way for more autonomous and adaptive models in the future” (DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning, Nature Oct. 2025).
To the refugee number theory acolyte, the confluence of the Banach Fixed Point Theorem and the theory of MDP strategies is pedestrian, such statements along with applications of the fundamental theorem of Linear Programming comprise the dual underpinnings of the (de-facto) formal basis for tabular value based methods derived from Bellman Optimality. Such value based frameworks are subsequently used as approximation targets for value and policy based networks in modern reinforcement learning. (cf. later references to DeepSeekR1 and Chain of Thought (CoT) driven reinforcement learning for generalized reasoning in LLMs). This is emphasized as it provides the underlying formal abstractions from the underlying two theorems that are never really placed in the front and center in most modern narratives on reinforcement learning.
Reinforcement Learning (RL) begins with a deceptively simple question: given that I am in some state at some point in time, what is the best strategy for maximizing present and future cumulative discounted rewards that can be attained over all possible present and future actions from the given initial state? The answer is crystallized in Richard Bellman’s principle of optimality seems states that the search over an infinite continuum of stochastic policies collapses, and there always exists a deterministic policy that is optimal – this result arises by application of the fundamental theorem of linear programming. This article unpacks how and why such a “Stochastic Collapse” (self-termed) occurs. It then describes the algorithmic structure that lets us compute the answer by working backward from the terminal time (Bellman backup and dynamic programming), and why such exact methods shatter against the scale of real-world problems—from autonomous vehicles to the reasoning chains inside large language models like DeepSeek-R1. For refugees more at home in number theory or cryptography than in control theory, the basic intuition behind behind the stochastic collapse is this: optimizing a value function over all stochastic policies is, on its face, an optimization over an uncountably infinite set of probability distributions—a simplex at every state and every time step. The key insight is that the structure of the Bellman equation forces the optimum to a vertex of each simplex, and vertices of probability simplices are precisely the deterministic (pure) actions. In a related vein, the parallel to Nash’s theorem on equilibria in non-cooperative games is not accidental; both rely on the geometry of simplices and fixed-point arguments, though the mechanisms diverge in important ways we will discuss.
2. Setup: Finite-Horizon MDPs, Policies, and Value Functions
2.1 The Finite-Horizon MDP
Definition (Finite-Horizon MDP). A finite-horizon Markov Decision Process is a tuple  where:
where:
 is a finite set of states,
is a finite set of states, is a finite set of actions,
is a finite set of actions, is the transition probability from state
is the transition probability from state  to
to  under action
under action  at time step
at time step  ,
, is the immediate reward for taking action in state at time step
is the immediate reward for taking action in state at time step 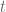 ,
, is the horizon—the number of decision epochs, and
is the horizon—the number of decision epochs, and![\gamma \in (0, 1]](https://s0.wp.com/latex.php?latex=%5Cgamma+%5Cin+%280%2C+1%5D&bg=ffffff&fg=516064&s=0&c=20201002) is a discount factor.
is a discount factor.
The agent interacts with the MDP for exactly  steps: at each time
steps: at each time  , it observes state
, it observes state  , selects action
, selects action  , receives reward
, receives reward  , and transitions to
, and transitions to  . The interaction terminates after step
. The interaction terminates after step  . Remark (Discount factor). In the finite-horizon setting, the discount factor
. Remark (Discount factor). In the finite-horizon setting, the discount factor  may be set to 1 without convergence issues, since the sum of rewards is bounded by at most terms. When
may be set to 1 without convergence issues, since the sum of rewards is bounded by at most terms. When  , the agent treats future rewards as equally valuable as immediate ones. We retain in the formulation for generality and to clarify the connection to the infinite-horizon discounted setting discussed in Section 5. Remark (Time-varying dynamics). We allow the transition kernel
, the agent treats future rewards as equally valuable as immediate ones. We retain in the formulation for generality and to clarify the connection to the infinite-horizon discounted setting discussed in Section 5. Remark (Time-varying dynamics). We allow the transition kernel  and reward function
and reward function  to depend on . This is the most general finite-horizon formulation. When
to depend on . This is the most general finite-horizon formulation. When  and
and  for all (time-homogeneous dynamics), the model simplifies, but the optimal policy may still be non-stationary because the time remaining influences the optimal action.
for all (time-homogeneous dynamics), the model simplifies, but the optimal policy may still be non-stationary because the time remaining influences the optimal action.
2.2 Non-Stationary Stochastic Policies
Definition (Non-stationary stochastic policy). A non-stationary stochastic policy is a sequence  where each
where each  maps states to probability distributions over actions at time . Here
maps states to probability distributions over actions at time . Here  denotes the
denotes the  -dimensional probability simplex:
-dimensional probability simplex:  Definition (Non-stationary deterministic policy). A policy
Definition (Non-stationary deterministic policy). A policy  is deterministic if, for every and ,
is deterministic if, for every and ,  places all probability mass on a single action—equivalently, is a vertex of . The space of all non-stationary stochastic policies is the Cartesian product
places all probability mass on a single action—equivalently, is a vertex of . The space of all non-stationary stochastic policies is the Cartesian product  a continuous, uncountably infinite set of dimension
a continuous, uncountably infinite set of dimension  .
.
2.3 The Gridworld Example
Example. Consider a gridworld state with four actions: Up, Down, Left, Right. At time step , a stochastic policy might assign  meaning: never go Up or Left, and flip a fair coin to decide between Down and Right. The space of all possible policies at this single state and time step is the 3-simplex—the tetrahedron in
meaning: never go Up or Left, and flip a fair coin to decide between Down and Right. The space of all possible policies at this single state and time step is the 3-simplex—the tetrahedron in  whose vertices are the four pure actions
whose vertices are the four pure actions  ,
,  ,
,  , and
, and  . At a different time step
. At a different time step  , the policy at the same state may assign an entirely different distribution—this is the non-stationary nature of finite-horizon policies. The number of remaining steps influences the optimal action: with many steps remaining, an exploratory detour may be worthwhile; with one step left, only the immediate reward matters.
, the policy at the same state may assign an entirely different distribution—this is the non-stationary nature of finite-horizon policies. The number of remaining steps influences the optimal action: with many steps remaining, an exploratory detour may be worthwhile; with one step left, only the immediate reward matters.
2.4 The State-Value Function
Under a fixed non-stationary policy , the value of state at time is the expected discounted cumulative reward from over the remaining horizon: ![\displaystyle V_t^\pi(s) = \mathbb{E}_\pi\!\left[ \sum_{k=0}^{H-1-t} \gamma^k \, R_{t+k}(s_{t+k}, a_{t+k}) \ \Big|\ s_t = s \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V_t%5E%5Cpi%28s%29+%3D+%5Cmathbb%7BE%7D_%5Cpi%5C%21%5Cleft%5B+%5Csum_%7Bk%3D0%7D%5E%7BH-1-t%7D+%5Cgamma%5Ek+%5C%2C+R_%7Bt%2Bk%7D%28s_%7Bt%2Bk%7D%2C+a_%7Bt%2Bk%7D%29+%5C+%5CBig%7C%5C+s_t+%3D+s+%5Cright%5D&bg=ffffff&fg=516064&s=0&c=20201002) At the terminal time
At the terminal time  , no further decisions are made, so the boundary condition is:
, no further decisions are made, so the boundary condition is:  The optimal value function at time is defined by optimizing over all non-stationary stochastic policies:
The optimal value function at time is defined by optimizing over all non-stationary stochastic policies:  On its face, this is an optimization over the product of simplices—a space with continuous dimensions. We now show that this optimization collapses dramatically.
On its face, this is an optimization over the product of simplices—a space with continuous dimensions. We now show that this optimization collapses dramatically.
3. The Stochastic Collapse: Why Deterministic Policies Suffice
3.1 The Bellman Optimality Equation (Finite Horizon)
The key structural result is the Bellman optimality equation for the finite-horizon setting. With the boundary condition  for all , the optimal value function satisfies, for
for all , the optimal value function satisfies, for  :
: ![\displaystyle V_t^*(s) = \max_{a \in \mathcal{A}} \left[ R_t(s,a) + \gamma \sum_{s' \in \mathcal{S}} P_t(s' \mid s, a)\, V_{t+1}^*(s') \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V_t%5E%2A%28s%29+%3D+%5Cmax_%7Ba+%5Cin+%5Cmathcal%7BA%7D%7D+%5Cleft%5B+R_t%28s%2Ca%29+%2B+%5Cgamma+%5Csum_%7Bs%27+%5Cin+%5Cmathcal%7BS%7D%7D+P_t%28s%27+%5Cmid+s%2C+a%29%5C%2C+V_%7Bt%2B1%7D%5E%2A%28s%27%29+%5Cright%5D&bg=ffffff&fg=516064&s=0&c=20201002) Notice the operator is
Notice the operator is  over the finite action set, not an optimization over probability distributions. This is not assumed—it is derived. We now show why.
over the finite action set, not an optimization over probability distributions. This is not assumed—it is derived. We now show why.
3.2 The Linearity Argument
Define the action-value function (or  -function) at time under optimality:
-function) at time under optimality:  Under a stochastic policy
Under a stochastic policy  , the value at state and time is the expectation over actions:
, the value at state and time is the expectation over actions:  This is a linear function of the policy weights . We are maximizing a linear functional over a convex polytope (the simplex). By a fundamental result in linear programming—indeed, by the same geometric argument that underlies the simplex method: Proposition (Vertex optimality on the simplex). Let
This is a linear function of the policy weights . We are maximizing a linear functional over a convex polytope (the simplex). By a fundamental result in linear programming—indeed, by the same geometric argument that underlies the simplex method: Proposition (Vertex optimality on the simplex). Let  be a linear function on the simplex with
be a linear function on the simplex with  . Then
. Then  and the maximum is attained at the vertex
and the maximum is attained at the vertex  where
where  . Proof. Since
. Proof. Since  , we have
, we have  and
and  . Let
. Let  . Then
. Then  with equality when
with equality when  .
.  Applying the Proposition with
Applying the Proposition with  :
:  This holds at every state and every time step , independently. Therefore the optimal policy is deterministic and non-stationary:
This holds at every state and every time step , independently. Therefore the optimal policy is deterministic and non-stationary: 
3.3 The Collapse Summarized
Theorem (Deterministic optimality in finite-horizon MDPs). For any finite-horizon MDP with ![\gamma \in (0,1]](https://s0.wp.com/latex.php?latex=%5Cgamma+%5Cin+%280%2C1%5D&bg=ffffff&fg=516064&s=0&c=20201002) , there exists a deterministic non-stationary policy
, there exists a deterministic non-stationary policy  that is optimal:
that is optimal:  Moreover,
Moreover,  for each and . This is the “stochastic collapse”: the optimization over
for each and . This is the “stochastic collapse”: the optimization over  —an uncountable product of simplices with continuous dimensions—reduces to
—an uncountable product of simplices with continuous dimensions—reduces to  independent
independent  operations, each over the finite set .
operations, each over the finite set .
3.4 Computational Significance
Without the collapse, finding an optimal policy would require searching over the continuous manifold . With the collapse, the search space reduces to  deterministic non-stationary policies—a finite (though exponentially large) set. More importantly, as we show in the next section, backward induction avoids enumerating even this finite set.
deterministic non-stationary policies—a finite (though exponentially large) set. More importantly, as we show in the next section, backward induction avoids enumerating even this finite set.
4. Computing the Optimum: Backward Induction
The Bellman optimality equation, combined with the boundary condition , yields a backward induction algorithm that computes  and
and  exactly. Algorithm: Backward Induction (Finite-Horizon Value Iteration)
exactly. Algorithm: Backward Induction (Finite-Horizon Value Iteration)
- Initialize: Set
 for all
for all  .
.
- For :
- For each and
 , compute:
, compute: 
- For each , set:

- Return
 and
and  .
.
Theorem (Correctness of backward induction). Backward induction computes the optimal value function and an optimal deterministic non-stationary policy  for any finite-horizon MDP. No initialization choice is required beyond the boundary condition
for any finite-horizon MDP. No initialization choice is required beyond the boundary condition  , which is given by the problem definition. Proof. By (backward) induction on . The base case is the boundary condition. For the inductive step, assume
, which is given by the problem definition. Proof. By (backward) induction on . The base case is the boundary condition. For the inductive step, assume  has been computed correctly. Then
has been computed correctly. Then  is correct, and by the Deterministic Optimality Theorem—itself a consequence of the Vertex Optimality Proposition—the over actions yields
is correct, and by the Deterministic Optimality Theorem—itself a consequence of the Vertex Optimality Proposition—the over actions yields  . Complexity. Each time step requires computing
. Complexity. Each time step requires computing  for all
for all  state-action pairs, and each involves a sum over
state-action pairs, and each involves a sum over  successor states. The total complexity is:
successor states. The total complexity is:  This is polynomial in the tabular quantities , , and
This is polynomial in the tabular quantities , , and  —a dramatic improvement over enumerating policies.
—a dramatic improvement over enumerating policies.
5. Connection to the Infinite-Horizon Discounted Setting
A parallel and widely-studied formulation is the infinite-horizon discounted MDP  with
with  , time-homogeneous dynamics, and no terminal time. Here is absent from the tuple; instead, the strict discount
, time-homogeneous dynamics, and no terminal time. Here is absent from the tuple; instead, the strict discount  ensures that the infinite sum of rewards converges. The value function under a stationary policy
ensures that the infinite sum of rewards converges. The value function under a stationary policy  is:
is: ![\displaystyle V^\pi(s) = \mathbb{E}_\pi\!\left[ \sum_{t=0}^{\infty} \gamma^t R(s_t, a_t) \;\Big|\; s_0 = s \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V%5E%5Cpi%28s%29+%3D+%5Cmathbb%7BE%7D_%5Cpi%5C%21%5Cleft%5B+%5Csum_%7Bt%3D0%7D%5E%7B%5Cinfty%7D+%5Cgamma%5Et+R%28s_t%2C+a_t%29+%5C%3B%5CBig%7C%5C%3B+s_0+%3D+s+%5Cright%5D&bg=ffffff&fg=516064&s=0&c=20201002) The Bellman optimality equation in this setting is:
The Bellman optimality equation in this setting is: ![\displaystyle V^*(s) = \max_{a \in \mathcal{A}}\left[ R(s,a) + \gamma \sum_{s'} P(s'|s,a)\, V^*(s') \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V%5E%2A%28s%29+%3D+%5Cmax_%7Ba+%5Cin+%5Cmathcal%7BA%7D%7D%5Cleft%5B+R%28s%2Ca%29+%2B+%5Cgamma+%5Csum_%7Bs%27%7D+P%28s%27%7Cs%2Ca%29%5C%2C+V%5E%2A%28s%27%29+%5Cright%5D&bg=ffffff&fg=516064&s=0&c=20201002) and the same linearity argument (Vertex Optimality Proposition) guarantees the existence of a deterministic stationary optimal policy.
and the same linearity argument (Vertex Optimality Proposition) guarantees the existence of a deterministic stationary optimal policy.
5.1 Value Iteration and the Banach Contraction Mapping Theorem
In the infinite-horizon setting, there is no terminal time from which to work backward. Instead, one defines the Bellman optimality operator  acting on value functions:
acting on value functions: ![\displaystyle (T^* V)(s) = \max_{a \in \mathcal{A}}\left[ R(s,a) + \gamma \sum_{s'} P(s'|s,a)\, V(s') \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%28T%5E%2A+V%29%28s%29+%3D+%5Cmax_%7Ba+%5Cin+%5Cmathcal%7BA%7D%7D%5Cleft%5B+R%28s%2Ca%29+%2B+%5Cgamma+%5Csum_%7Bs%27%7D+P%28s%27%7Cs%2Ca%29%5C%2C+V%28s%27%29+%5Cright%5D&bg=ffffff&fg=516064&s=0&c=20201002) and applies it iteratively:
and applies it iteratively:  , starting from an arbitrary initialization
, starting from an arbitrary initialization  . Convergence is guaranteed by the following classical result. Theorem (Banach Fixed-Point Theorem). Let
. Convergence is guaranteed by the following classical result. Theorem (Banach Fixed-Point Theorem). Let  be a complete metric space and
be a complete metric space and  a contraction mapping, i.e., there exists such that
a contraction mapping, i.e., there exists such that  Then: (i)
Then: (i)  has a unique fixed point
has a unique fixed point  ; (ii) for any
; (ii) for any  , the sequence
, the sequence  converges to
converges to  ; (iii) the rate of convergence satisfies
; (iii) the rate of convergence satisfies  The space of bounded value functions
The space of bounded value functions  equipped with the supremum norm
equipped with the supremum norm  forms a complete metric space (a finite-dimensional Banach space). The operator is a -contraction under this norm:
forms a complete metric space (a finite-dimensional Banach space). The operator is a -contraction under this norm:  which follows from the non-expansiveness of the operator and the -scaling of the future terms. By the Banach theorem: (i)
which follows from the non-expansiveness of the operator and the -scaling of the future terms. By the Banach theorem: (i)  is the unique fixed point of ; (ii) value iteration converges to from any initialization ; (iii) convergence is geometric with rate , yielding an
is the unique fixed point of ; (ii) value iteration converges to from any initialization ; (iii) convergence is geometric with rate , yielding an  -approximate solution in
-approximate solution in  iterations. Each iteration has complexity
iterations. Each iteration has complexity  , giving a total complexity of:
, giving a total complexity of:  Remark (Finite vs. infinite horizon). The two settings are related but structurally distinct. In the finite-horizon case, convergence is trivial—backward induction terminates in exactly steps from the known boundary . In the infinite-horizon case, there is no boundary condition; convergence must be proved, and the Banach theorem provides this guarantee. One can embed a finite-horizon problem into an infinite-horizon one by augmenting the state space with a time index and introducing an absorbing terminal state, but this is an encoding device rather than a natural subsumption. An alternative exact method for the infinite-horizon setting, Policy Iteration (Howard, 1960), alternates between policy evaluation (solving a
Remark (Finite vs. infinite horizon). The two settings are related but structurally distinct. In the finite-horizon case, convergence is trivial—backward induction terminates in exactly steps from the known boundary . In the infinite-horizon case, there is no boundary condition; convergence must be proved, and the Banach theorem provides this guarantee. One can embed a finite-horizon problem into an infinite-horizon one by augmenting the state space with a time index and introducing an absorbing terminal state, but this is an encoding device rather than a natural subsumption. An alternative exact method for the infinite-horizon setting, Policy Iteration (Howard, 1960), alternates between policy evaluation (solving a  linear system) and greedy policy improvement. It converges in finitely many iterations (at most
linear system) and greedy policy improvement. It converges in finitely many iterations (at most  , though typically far fewer), with each iteration costing
, though typically far fewer), with each iteration costing  for the linear solve.
for the linear solve.
6. Connection to Game-Theoretic Equilibria
The vertex-of-the-simplex phenomenon has a notable parallel in non-cooperative game theory. Nash’s Existence Theorem guarantees the existence of mixed-strategy equilibria in finite games via Kakutani’s fixed-point theorem applied to best-response correspondences over strategy simplices. In certain structured games—including two-player zero-sum games (the minimax theorem, von Neumann 1928)—the equilibrium may be achieved in pure strategies. The analogy is instructive but the mechanisms differ. In single-agent MDPs (both finite and infinite horizon), the optimality of deterministic policies follows from the linearity of the objective in the policy at each state and time step, combined with the simplex geometry. It is a consequence of LP duality, not a fixed-point existence argument. In multi-agent games, pure-strategy equilibria are not guaranteed in general. The minimax theorem for zero-sum games relies on saddle-point structure, and Nash equilibria in general games may require genuinely mixed strategies. The single-agent MDP is thus a more favorable setting: the linearity structure is stronger than what multi-agent interactions provide, and deterministic optima are guaranteed rather than merely possible.
7. The Curse of Dimensionality: Why Exact Methods Fail at Scale
Both backward induction and infinite-horizon value iteration are tabular methods: they maintain an explicit table of values for every state (and possibly every state-action pair) at every time step. Their per-iteration complexity is polynomial in —but itself is the problem. In real-world applications, the state space grows combinatorially or continuously: Autonomous driving. The state includes the ego vehicle’s position, velocity, and heading; the positions and velocities of dozens of surrounding agents; lane geometry; traffic signal states; weather conditions; and sensor uncertainty. Even a coarse discretization yields state spaces of  or more. The horizon can span hundreds of decision steps at 10 Hz control frequency. Storing a single floating-point value per state per time step is physically impossible, let alone iterating over them. The complexity bound
or more. The horizon can span hundreds of decision steps at 10 Hz control frequency. Storing a single floating-point value per state per time step is physically impossible, let alone iterating over them. The complexity bound  becomes vacuous. LLM reasoning (DeepSeek-R1 and GRPO). DeepSeek-R1 uses reinforcement learning—specifically Group Relative Policy Optimization—to train a large language model to perform multi-step reasoning. Here, a “state” at time is the entire sequence of tokens generated so far (the partial chain of thought), and an “action” is the next token from a vocabulary of ~100,000. The state space is the set of all possible token sequences up to the context length—a number that dwarfs any astronomical quantity. The horizon is the maximum generation length (often thousands of tokens). The value function (estimating the quality of a partial reasoning chain) cannot be tabulated; it must be approximated, which is exactly what the neural network serves as. In this setting, the non-stationary nature of the finite-horizon formulation is particularly natural: the quality of a token choice depends critically on how many reasoning steps remain.
becomes vacuous. LLM reasoning (DeepSeek-R1 and GRPO). DeepSeek-R1 uses reinforcement learning—specifically Group Relative Policy Optimization—to train a large language model to perform multi-step reasoning. Here, a “state” at time is the entire sequence of tokens generated so far (the partial chain of thought), and an “action” is the next token from a vocabulary of ~100,000. The state space is the set of all possible token sequences up to the context length—a number that dwarfs any astronomical quantity. The horizon is the maximum generation length (often thousands of tokens). The value function (estimating the quality of a partial reasoning chain) cannot be tabulated; it must be approximated, which is exactly what the neural network serves as. In this setting, the non-stationary nature of the finite-horizon formulation is particularly natural: the quality of a token choice depends critically on how many reasoning steps remain.
7.1 The Approximation Paradigm
The modern response to the curse of dimensionality is function approximation: rather than storing  or in a table, represent them with a parameterized function—a neural network, a linear combination of features, or another compact representation:
or in a table, represent them with a parameterized function—a neural network, a linear combination of features, or another compact representation:  This introduces both power and peril. Deep Q-Networks (DQN, Mnih et al., 2015) demonstrated that neural networks could approximate
This introduces both power and peril. Deep Q-Networks (DQN, Mnih et al., 2015) demonstrated that neural networks could approximate  well enough to achieve superhuman Atari play directly from pixels. Proximal Policy Optimization (PPO, Schulman et al., 2017) and its descendants optimize parameterized stochastic policies directly via gradient ascent, sidestepping the need to ever represent or in full. The clean convergence guarantees of backward induction (finite horizon) and the Banach theorem (infinite horizon) no longer apply in their original form—function approximation can cause divergence (the “deadly triad” of off-policy learning, function approximation, and bootstrapping). Ensuring stability in this regime remains one of the central open problems in RL theory.
well enough to achieve superhuman Atari play directly from pixels. Proximal Policy Optimization (PPO, Schulman et al., 2017) and its descendants optimize parameterized stochastic policies directly via gradient ascent, sidestepping the need to ever represent or in full. The clean convergence guarantees of backward induction (finite horizon) and the Banach theorem (infinite horizon) no longer apply in their original form—function approximation can cause divergence (the “deadly triad” of off-policy learning, function approximation, and bootstrapping). Ensuring stability in this regime remains one of the central open problems in RL theory.
8. Conclusion
The essence of Bellman optimality is the dramatic simplification hidden inside an apparently intractable optimization problem. The scaling limitations of dynamic programming based methods motivate the need for alternatives based on approximate rather than exact solutions – follow on articles in this series will introduce approximate methods starting with Deep Q Learning and then move over to a discussion of policy networks starting with the so called “Reinforce Trick” and culminating in a description of the PPO Surrogate Objective function.
