Props to Pivotal for supporting work on my recent internet draft on post quantum KEX from RLWE. Access the IRTF/IETF draft through the link below:
Slides from a recent presentation on homomorphic encryption schemes based on approximate GCD, learning with errors (LWE) and ring LWE assumptions (link below):
Fully Homomorphic Encryption from the Ring-LWE Assumption
Slides from a recent talk on secure computation / zero knowledge proofs (click on the link below):
MultiParty Computation : Zero Knowledge Proofs : Oblivious Transfer
The following is a post on the concrete security of symmetric encryption, focused primarily on the work of Bellare, Desai, Jokipii and Rogaway [BDJR1997], which builds on prior work of Goldwasser and Micali on the notions of semantic security and ciphertext indistinguishability in a complexity theoretic setting. The [BDJR1997] work views these concepts in the context of symmetric encryption and presents the additional notions of left-or-right and real-or-random indistinguishability followed by what are in all but a single case security preserving reductions between the notions in the CPA and CCA sense.
Following this [BDJR1997] provides a concrete security analysis of some of the prevalent modes of operation, of interest to us here are the counter modes. There are two such modes discussed, the 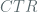
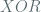


The theorem of interest from the paper for AES counter modes we consider is the following (Theorem 11), related to the
![\textbf{Adv}^{lor-cpa}_{XOR[F]}(\dot,t,q_{e},\mu_{e}) \leq 2 \cdot \textbf{Adv}^{prf}_F + \frac{\mu_{e} \cdot (q_{e} -1)} { L \cdot 2^{l}}](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BF%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29+%5Cleq+2+%5Ccdot+%5Ctextbf%7BAdv%7D%5E%7Bprf%7D_F+%2B+%5Cfrac%7B%5Cmu_%7Be%7D+%5Ccdot+%28q_%7Be%7D+-1%29%7D+%7B+L+%5Ccdot+2%5E%7Bl%7D%7D&bg=ffffff&fg=516064&s=0&c=20201002)
In the above expression, ![\textbf{Adv}^{lor-cpa}_{XOR[F]}(\dot,t,q_{e},\mu_{e})](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BF%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29&bg=ffffff&fg=516064&s=0&c=20201002)

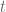


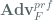
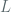
![XOR[F]](https://s0.wp.com/latex.php?latex=XOR%5BF%5D&bg=ffffff&fg=516064&s=0&c=20201002)
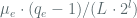
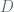

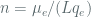

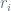


![\textbf{Adv}^{lor-cpa}_{XOR[R]}(\dot,t,q_{e},\mu_{e}) \leq \frac{\mu_{e} \cdot (q_{e} -1)} { L \cdot 2^{l}}](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BR%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29+%5Cleq%C2%A0+%5Cfrac%7B%5Cmu_%7Be%7D+%5Ccdot+%28q_%7Be%7D+-1%29%7D+%7B+L+%5Ccdot+2%5E%7Bl%7D%7D&bg=ffffff&fg=516064&s=0&c=20201002)
Where ![\textbf{Adv}^{lor-cpa}_{XOR[R]}(\dot,t,q_{e},\mu_{e})](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BR%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29&bg=ffffff&fg=516064&s=0&c=20201002)
![XOR[R]](https://s0.wp.com/latex.php?latex=XOR%5BR%5D&bg=ffffff&fg=516064&s=0&c=20201002)
Assuming 
![\textbf{Adv}^{lor-cpa}_{XOR[F]}(\dot,t,q_{e},\mu_{e}) \leq 2 \cdot \epsilon + \omega](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BF%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29+%5Cleq+2+%5Ccdot+%5Cepsilon+%2B+%5Comega&bg=ffffff&fg=516064&s=0&c=20201002)
where 
An Example
We now use the bounds derived above to get a sense of the advantage for an AES “randomized” counter-mode. In this case we set 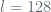





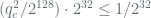


Therefore, in our example, to confine the LOR-CPA advantage below
On the other hand, limiting the distinguishing advantage to 


Encrypting Large Volumes
We now turn the discussion to requirements around rotating keys in scenarios where potentially large volumes of data at rest are encrypted – while other sites such as the Kubernetes’ encrypting data at rest page attempt to provide such guidance by providing bounds on the amount of data encrypted with a fixed key, they fail to explicitly do so from the standpoint of the distinguishing arguments and privacy / forgery bounds presented in [BDJR1997], whereas this post seeks to motivate limits on key usage from this viewpoint (later on, however, we’ll consider other factors around limiting key usage and lifespan independent of the concrete analysis). The Kubernetes page, for instance, prescribes a limit of 200K (
To recap, in order to confine the adversary’s LOR-CPA distinguishing advantage below 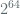
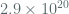

Limitations and Ambiguities in the GCM Spec.
NIST SP 800-38D limits the message size for a single GCM message at 
Guidance on CCM Parameters
As an alternative to GCM, CCM authenticated encryption mode could be considered for encrypting larger volumes of data owing to larger specified privacy bonds (that we will discuss below). Unlike GCM, however, CCM does not offer the ability to compute the MAC in parallel, however, we do not view this as a concern in an offline encryption / decryption scenario. Also, CCM is not on-line in the sense that the length of the message must be known beforehand. On the other hand CCM, like GCM, is a NIST approved mode of operation which is of particular benefit in environments that require a high level of review. Moreover, CCM does not from a specification viewpoint have an explicit 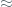
It is important to note that in the [BDJR1997] description of the 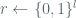
The length of the nonce is specified by the parameter ‘n’ and the spec allows for this to be 7, 8, 9, 10, 11, 12, or 13 bytes. The plaintext length in bytes, denoted ‘p’, is formatted as an octet string denoted Q in the first input block. The length of Q in bytes, is denoted q where q can take on the values 2, 3, 4, 5, 6, 7, 8 subject to the constraint n + q = 15. The value of q determines the max. size for a given message which is 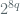

q = 5
This parameter allows message sizes upto 
n = 10
Finally we specify the length of the tag in octets as:
t = 16
We recommend a key size of 256 bits.
Rationale
Why do we select the following parameters? The selection is primarily driven by the need for designing a method that will aid in ease of implementation while remaining secure. Though implementors will chunk inputs under the 1.1 TB limit owing to buffering limits (see later section on discussion on the OpenSSL CCM API), they are theoretically not required to do so with the specified parameters. Another goal for the specified parameters is to make the nonce space large – the rationale for this is that we cannot control how implementors will generate the nonces. The privacy analysis of CCM is based on the assumption of a nonce-respecting adversary that does not repeat nonces across invocations. In practice, however, since the nonce must be supplied by the user as input to the scheme, we are not entirely confident that users will be nonce-respecting. They may randomly sample nonces. Given this fact, we think it prudent to specify a larger nonce space to reduce the likelihood of collisions while limiting the number of distinct messages encrypted with a given key (but at the same time discourage the use of random nonces). Then, for illustration purposes, we’ll consider the overall privacy bounds for the parameters specified above by limiting the number of distinct messages encrypted under a given key to 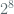
While we have thus far discussed limits on key usage from a concrete security standpoint, there are several reasons to rotate keys before such data limits are reached, significant among those reasons being leakage of all or parts of the key – fragmenting of data into smaller portions and generating distinct data encrypting keys per fragment limits the amount of information leaked in the event that a single key is compromised. While implementors should consider these facts and may refer to extant practice on this subject, for instance, here, we once more emphasize the primary goal of this exercise is to talk about actual limits arising from the concrete privacy bounds.
Returning to our parameters, the max limit on the number of block cipher calls for a given key is 

Key Wrapping
As mentioned, there are compelling reasons to fragment data, encrypt, and then spread it across different physical volumes. In this case, it can be beneficial to locate the data encryption key near or along with the data being encrypted. For these scenarios, we recommend key wrapping of the data encrypting key with AES-256 GCM (refer to internal Pivotal standards for these ciphers). Ideally, the key encrypting key should be stored in an HSM. We do not currently advocate the use of key wrapping mechanisms in NIST Special Publication 800-38F “Recommendation for Block Cipher Modes of Operation: Methods for Key Wrapping”.
Appendix A: CCM Privacy Bounds
Here, we relay the concrete privacy bounds provided by Jakob Jonsson, which are stated as:
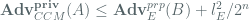
where
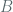



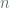



This post discusses the security of NIST prime curves (i) given the compromised status of Dual_EC_DRBG, (ii) and in light recent announcements from the NSA’s IAD which can be found here:
https://www.nsa.gov/ia/programs/suiteb_cryptography/
Interestingly, the agency has also stated that “With respect to IAD customers using large, unclassified PKI systems, remaining at 112 bits of security (i.e. 2048-bit RSA) may be preferable (or sometimes necessary due to budget constraints) for the near-term in anticipation of deploying quantum resistant asymmetric algorithms upon their first availability”.
The intent of this post is to try and question some theories around deliberate specification of weak curves by selection of “weak seed” inputs to the SHA-1 function as part of the ANSI / NIST curve generation process. The reasoning presented expands on implied requirements around the number of weak curves that must exist over 256 bit prime fields in order for such theories to hold.
Weak Curves:
It is widely known that certain classes of “weak curves” exist where the standard ECDLP problem is reduced to a simpler problem. For example, attacks on curves which leverage pairings are documented in the literature. Such attacks leverage bilinear maps 



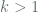


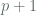
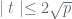
Koblitz and Menezes (KM2015):
For the rest of this post, we’ll dissect some parts of a post Snowden defense of ECC authored by Koblitz and Menezes, two mathematicians of high repute (Koblitz in particular is the co-inventor of elliptic curve cryptography, author of the landmark text “A Course in Number Theory and Cryptography”, and noted sceptic of reductionist methods / provable security) . The ECC defense is entitled “An Riddle Wrapped in an Enigma” published here –
The line of thought we’re concerned with traces lineage of the NIST prime curves to NSA involvement in the ANSI X9F1 committee, the exact nature of NSA involvement is not well outlined in the paper, but the implication is that NSA was willing to generate curves on behalf of the ANSI effort, and at the time, had the technology to enumerate orders of the resulting groups.
In order to ensure that known weak curves (known to the NSA, that is) were not selected, it was decided that curve co-efficients be selected by passing a seed to the SHA-1 function. The security of this method would be assured given the fact that it’s hard to invert SHA-1, i.e., in the event that NSA was aware of certain weak curves, it would be hard to find the SHA-1 pre-image that would result in the required co-efficients for the weak curve.
So this brings us to one of the primary arguments against security of the prime curves, and it’s centered on the provenance / legitimacy of the SHA-1 seeds used for curve generation. In the vein of classic conspiracy theories, the argument goes that the NSA could have known about “many” weak curves, and repeatedly picked random seeds until one of the seeds resulted in a weak curve. Koblitz and Menezes in the referenced paper refute this line of thought by arguing that in order to find a seed for a weak prime curve in 
For a field 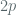

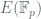
With 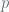

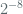
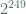

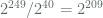
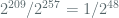
KM2015 then proceed to argue that for a 256 bit prime,
Deep Crack: Bespoke Silicon Circa 1998
Though KM2015 go on to cite other possible reasons for dropping p-256, including adaptations of Bernstein and Lange’s so called 

Conclusions:
It is not the intent of the author to promote the view that there are a large number of weak curves nor that the NSA exploited this fact to pre-determine SHA-1 seeds in order to ensure selection of weak curves and their eventual standardization through NIST. The situation with weak curves is quite different from that of Dual_EC_DRBG, since in some sense, eventual knowledge of such weak curves would confer an “equal opportunity” advantage to anyone with cryptanalytic ability, rather than bestowing an asymmetric advantage to any one party. Rather, the point of this post is to merely trace reasoning around existence of weak curves and provide more insight around quantifying the size of classes of purported weak curves. If one allows NSA to have about 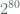
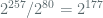
“Although there is no plausible reason to mistrust the NIST curves, there are two reasons why it is nevertheless preferable to use other curves .. The first reason is public perception — even though it is unlikely that the NIST curves are unsafe, there has been enough speculation to the contrary that to keep everybody happy one might as well avoid the NIST curves. The second reason is that the other curves do have some advantages … It is no discredit to the NIST curves that more efficient alternatives are now available — after all, it has been 18 years, and it would be surprising if no one had come up with anything better by now”
Recommended Cryptographic Primitives and TLS Suites
The following is a list of cryptographic primitives and TLS cipher suites. They should be adhered to in order to provide a minimal or “baseline” level of security for software and firmware components. Most of the algorithms cited here are described in standards published by the US National Institute of Standards and Technology (NIST). The list also outlines algorithms and key length requirements that are likely to be encountered for DoD applications, since the requirements for these types of applications are often more stringent than what is permitted by the NIST.
Cryptographically Secure Pseudo Random Number Generation (CSPRNG)
For generation of IVs, nonces, challenges and salts (These terms are defined in the course of this document).
1)Hash_DRBG based on SHA256
2)Hash_DRBG based on SHA384 (minimal requirement for DoD applications)
This functionality will normally be provided by your programming language or API (eg. java.security.SecureRandom or rand() rand_bytes() defined in the header OpenSSL header rand.h)
In some cases, you may have to use the above random number generator directly for symmetric (AES) key generation – this is generally OK for AES key generation especially when no other method for generating the AES key is available. Other programing languages will provide you with a direct interface to generate symmetric keys. It is generally not appropriate to directly use these generators for creating RSA, ECC, or Diffie Hellman keys. Modern programming language interfaces should provide you with functions for generating this latter class of key (eg. RSA_generate_key() defined in the OpenSSL header rsa.h). The above generators are typically seeded with input from a true entropy source, which in the case of Linux is /dev/random (NIST standards also allow one to augment the input from the true entropy source with a “nonce” and a “personalization string”, but the programming interface should typically shield you from these details). Though the periodicity of the above CSPRNGs is extremely high, in some rare cases, it may be relevant to re-seed the CSPRNG from the physical source at some point in time after its instantiation.
(Advanced Note: The draft standard NIST SP 800-90C outlines methods for constructing pseudo-random number generators, also referred to as deterministic random number generators (or “DRBGs”, such as the one listed above), by specifying how to combine entropy sources with a DRBG. We are not currently considering this standard, since at the time of writing, it is still in draft form)
True Random Number Generation (TRNG)
True random number generation (also called non-deterministic random number generation) generally refers to the construction of entropy sources. At the time of writing, we have no recommendations for this other than use of /dev/random, but are tracking development of the draft NIST SP 800-90B standard that specifies multiple TRNG mechanisms.
10.3 Symmetric Encryption
- AES-128-GCM_16
- AES-256-GCM_16 (minimal requirement for DoD applications)
AES GCM encrypts an input stream and then computes an authentication tag over the ciphertext. The tag length should be 16 bytes. Every distinct message that is encrypted requires that a distinct random string of bits, called an IV is provided as input to the AES ciphering function in addition to the key and the plaintext message. The IV input should be 12 bytes. The AES key should be rotated after a maximum of $2^32$ encryptions. It is critically important to the security of GCM that the IVs used to encrypt two distinct messages under GCM are in turn distinct. There are two methods to construct IVs for GCM, the first being the so called deterministic method the second, the so called “RBG” method. The RBG method should be used with the secure random number generator listed above. Some programming languages and interfaces may require that you directly use a random number generator to generate the AES key (eg. rand_bytes() in the OpenSSL header rand.h). Other programming languages provide you with an interface to do so (eg. the java.security KeyGenerator and java.security.SecretKey classes)
Digital Signature Algorithms
- RSASSA-PKCS1-v2.1
Applications can use either of the above RSA based signing algorithms with modulus size 3072 bits. The RSA public exponent should be 65537. There is an alternative (provable secure) RSA based signature scheme which utilizes probabilistic padding (PSS). We don’t currently include this scheme owing to a greater number and variation in parameters required for this signature scheme, but it may be included for use in the future.
Advanced note on the generation of RSA keys – it is expected that a programming interface is available for the generation of RSA keys (for eg. the function RSA_generate_key() in the OpenSSL header rsa.h.) In some cases, the key generation interface may presuppose instantiation of an appropriately seeded random number generator (refer to discussion on CSPRNGs above). It is generally expected that prime number generation for the programming interface uses an approved method for testing primes, such as the methods specified in the FIPS 186-4 appendices)
Hash Functions
- SHA-256
- SHA-384 (minimal requirement for DoD applications)
Keyed Message Authentication Codes
In a loose sense, the RSA based digital signature scheme above can be thought of as a way to authenticate and verify the integrity of a message received from the holder of a RSA private key. In a similar vein, a keyed message authentication code (MAC) can be thought of as a way to authenticate and verify the integrity of a message received by the holder of a secret key, though in this case, the sender and the receiver must possess the same secret key. The following keyed MACs should be used
- HMAC (with SHA256)
- HMAC (with SHA384 minimal requirement for DoD applications)
- GMAC
HMAC is a hash function based key message authentication code. It should be used with a key size of 256 bits or 384 bits depending on the size of the hash function output.
GMAC is a keyed message authentication function based on the GCM GHASH function. GMAC should be minimally be used with a key size of 128 bits. In addition, the IV size should be 96 bits and an output tag length should be 128 bits. For generation of keys and IVs related to GMAC, refer to the above discussion on AES-128-GCM_16
Elliptic Curves
The primary reason for providing guidance on elliptic curves is owing to their relevance to key exchange mechanisms within recommended TLS cipher suites described later. The following NIST “prime” curve should be used:
- NIST P-384
(Note: At the time of writing, this is the only curve currently allowed in DoD environments. The higher strength P-521 curve is generally disallowed)
Diffie Hellman Groups
Once more, the primary reason for providing guidance on Diffie Hellman (DH) groups is owing to their relevance to key exchange mechanisms within recommended TLS cipher suites described later. It is recommended that only DH groups with a prime modulus of 3072 bits or higher from RFC 3526 (i.e. “MODP group” ids 15 – 18) be used.
Asymmetric Encryption
- RSA-OAEP with 2048 bit modulus
RSA-OAEP requires a hash and mask generation function, it should be used with SHA-256 and mask generation function MGF1
(Note: Analysis on specification of OAEP with SHA-384 for DoD applications is pending)
Password Hashing
- Bcrypt with 128 bit salt and a minimal load factor of 10 of regular users and 12 for privileged users.
Password Based Key Derivation
- pbkdf2 – analysis pending
TLS Cipher Suites
The following cipher suites are recommended in order to secure internal PCF communications. The reader will notice that the following cipher suites only utilize the algorithms specified in the preceding sections. We do not currently consider it feasible to constrain cipher suites for external clients.
TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 (DoD compliant algorithms)
TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (DoD compliant algorithms)
EC suites should only use the NIST P-384 curve (as per section above)
DH suites should only use the DH groups specified in the section above.
RSA signatures should conform to the requirements stated above
(Note: the following facts are currently unknown (1) is P-384 supported with AES-128 suites, the standards are not clear on this, it may be implementation dependent (2) are DH groups 15 – 18 supported with AES-128 suites on all programming stacks? Curve P-384 and (minimally), the DH group id 15 should be supported with the AES-256 suites)
Fully homomorphic encryption has evolved from Craig Gentry’s original work based on worst case problems in ideal lattices and problems based on sparse subset sums, to newer schemes such as the BGV Ring Learning With Errors (LWE) scheme (based on lattice SVP) – This is a scheme where the plaintext space is taken to consist of integer subrings 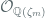
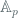
![\mathbb{Z}[X]/\langle \Phi_m(X),p \rangle](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5BX%5D%2F%5Clangle+%5CPhi_m%28X%29%2Cp+%5Crangle&bg=ffffff&fg=516064&s=0&c=20201002)


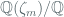
To expand on this notion, consider a ‘somewhat’ homomorphic scheme 

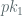




1)
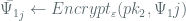
2)

Where 

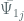



In the context of privacy preserving outsourced computation, the Recrypt procedure described would typically be evaluated by an untrusted counterparty. Therefore, it cannot compromise the security of secret keys (This is the case since
Lets take a step back and consider some essential aspects of the problem and of Gentry’s original scheme – Fully homomorphic encryption (FHE) schemes allow for the computation of arbitrary functions on encrypted data viz. you can do anything on the data that can be efficiently expressed as a circuit. FHE schemes have eluded cryptographers for at least 3 decades. In 2009 Craig Gentry published an initial scheme based on the ideal coset problem instantiated over ideal lattices, that is lattices corresponding to ideals in polynomial rings of form ![\mathbb{A} = \mathbb{Z}[X] / \Phi_m(X)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BA%7D+%3D+%5Cmathbb%7BZ%7D%5BX%5D+%2F+%5CPhi_m%28X%29+&bg=ffffff&fg=516064&s=0&c=20201002)

Specifically, in his initial somewhat homomorphic construction, Gentry employs computational assumptions around the ideal coset problem (ICP) – when instantiated over ideal lattices. this is equivalent to the so called the bounded distance decoding problem (BDDP). The second computational assumption used involves sparse subset sums – this arises out of a requirement to ‘squash’ the decryption circuit in order to address its essential non-compactness . At the time, lattices were chosen to further minimize complexity of the decryption circuit and facilitate the bootstrap while maximizing the scheme’s evaluative capacity – decryption in lattice based schemes is typically dominated by matrix vector multiplication (NC1 complexity). Contrast this to RSA, for instance, that requires evaluating modular exponents.
To recap, a central aspect of Gentry’s result is precisely bootstrapping, which brings us to US patent 2011/0110525 A1 granted May 12 2011 “Fully homorphic encryption method based on a bootstrappable encryption scheme, computer program and apparatus” (Asignee IBM). Within the detailed description of the invention, the following is stated – “It is shown that if the decryption circuit of a somewhat homomorphic encryption scheme is shallow enough, in particular, if it is shallow enough to be evaluated homomorphically by the somewhat homomorphic scheme itself (a self-referential property), then this somewhat homomorphic scheme becomes “bootstrappable”, and can be used to construct a fully homomorphic scheme that can evaluate circuits of arbitrary depth.” The description within the remaining text of the patent is essentially a distillation of Gentry’s 2009 thesis. So on the face of it, it does look like bootstrapping is covered by the patent.
There is the lingering question of the applicability of this (or other) patents to the “leveled” scheme of Brakerski, Gentry, Vaikuntanathan (BGV) published in 2011. This is a fully homomorphic scheme based on the learning with errors (LWE) or Ring-LWE (RLWE) problem/s. Rather than bootstrapping as a noise management technique, BGV starts with somewhat homomorphic encryption and uses tensor products along with a process called re-linearization and modulus switching to maintain the relative magnitude of ciphertext noise during homomorphic evaluation, but does propose bootstrapping as an optimization for evaluating deeper circuits that otherwise in the purely leveled scheme may require very large parameter choices for “aggregate” plaintext / ciphertext rings.
Concerning references and the attribution of results – the work discussed spans multiple groups and individuals including Craig Gentry, Vinod Vaikuntanathan, Shai Halevi, Zvika Brakerski, Nigel Smart, F. Vercauteren, Adriana Lopez-Alt and Eran Tromer to name a few.
This post picks up at the point of considering BGV (Brakerski, Gentry, Vaikuntanathan) encryption variants based on Ring-LWE. Thought it may seem natural to start by considering the BGV enciphering function, I will avoid discussing this since is actually quite simple in principle and essentially consists of polynomial mixing and sampling from an error distribution. Also, it is described well in a post on Windows on Theory by Boaz Barak and Zvika Brakerski that can be found here:
Instead, I’d like to delve into the plaintext algebra of the “Ring-LWE” BGV variant in order to understand the encoding / representation of plaintext bits in the scheme . In this post, we consider the idea of batched homomorphic operations and so called ‘plaintext slots’, along with some of the basic algebra that supports the specification of plaintext slots.
In particular, we consider the Ring-LWE BGV variant defined over rings of form:


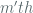


Note that the cyclotomic polynomial factors into r irreducible factors mod 2 (which follows partially from the fact that the cyclotomic extension

Lets cover some background around Chinese Remaindering and homomorphisms of rings – Consider ![F(X) \in \mathbb{F}_2[X]](https://s0.wp.com/latex.php?latex=F%28X%29+%5Cin+%5Cmathbb%7BF%7D_2%5BX%5D&bg=ffffff&fg=516064&s=0&c=20201002)
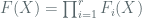
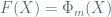
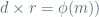
![A = \mathbb{F}_2[X]/(F(X))](https://s0.wp.com/latex.php?latex=A+%3D+%5Cmathbb%7BF%7D_2%5BX%5D%2F%28F%28X%29%29&bg=ffffff&fg=516064&s=0&c=20201002)
which is the quotient of ![\mathbb{F}_2[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D_2%5BX%5D&bg=ffffff&fg=516064&s=0&c=20201002)
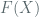
By the Chinese remainder theorem, there is the isomorphism:
![A \cong \Bbb{F}_2[X]/F_1(X) \otimes \Bbb{F}_2[X]/F_2(X) \otimes\dots\otimes \Bbb{F}_2[X]/F_r(X)](https://s0.wp.com/latex.php?latex=A+%5Ccong+%5CBbb%7BF%7D_2%5BX%5D%2FF_1%28X%29+%5Cotimes+%5CBbb%7BF%7D_2%5BX%5D%2FF_2%28X%29+%5Cotimes%5Cdots%5Cotimes+%5CBbb%7BF%7D_2%5BX%5D%2FF_r%28X%29&bg=ffffff&fg=516064&s=0&c=20201002)

So that 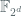
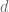
This captures central idea around the of batching homomorphic operations -We start by encoding individual bits in the 
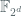
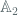
![\mathbb{Z}_2[X]/F_i(X)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D_2%5BX%5D%2FF_i%28X%29&bg=ffffff&fg=516064&s=0&c=20201002)
‘Entropy’, in the context of the Linux Random Number Generator (‘LRNG’), is an accretional quantity arising the uncertainty of hardware generated interrupt time stamps. If you’re already familiar with the mechanism, bear with me as I provide some intuition – consider timestamp parity and think of the kernel appending 0 to a stored register value if the millisec counter on an interrupt timestamp is even parity, or 1 if it’s odd, and then generating a string of random bits this way after witnessing many interrupts. The string of resulting bits can then be read out of the register for applications that require randomness, at which point the value is reset to zero. If we admit that even parity on timestamps is as likely as odd, it’s clear that the uncertainty (i.e., the entropy) in bitstrings from this construction is a function of the length of the strings : The greater the number of observed interrupts -> the longer the string -> the higher the entropy. Here is a simple illustration – assume that I create a 3 bit random string by observing the parity of three successive interrupt time values (measured in milliseconds since system boot). If these time values are 


The LRNG does not actually generate random bits this way (that is, by concatenating interrupt millisec time values modulo 2). Roughly, the actual method is based on uncertainty in interrupt times represented as ‘jiffies’, 32 bit words representing time of an interrupt in millisecs since system boot, along with a ‘high resolution’ time value obtained from the CPU. These values are ‘mixed’ into the entropy ‘pools’ from where an extraction function creates sequences of pseudo-random bits on demand. This is concretely described in Gutterman, Pinkas et. al’s description of breaks to backtracking resistance of the LRNG [GPR 2006]. The goal of this piece, however, is not to address weaknesses like the analytic breaks discussed above, it’s to try and address looming confusion on a couple of fronts including (i) general suitability of the LRNG pools, including the non blocking ‘urandom’ pool, for ciphering (ii) issues with the quality of randomness arising from virtualization, including arbitration and biasing of otherwise random processes by a hypervisor hosting multiple guest systems on shared hardware (iii) the conflation of virtualization and biasing effects mentioned above, with the effects of app containerization on a single VM.
Rather than expound on all the above, let’s address the suitability of the LRNG for ciphering, after which, perhaps we outline a discussion on real or perceived biasing of timestamp values due to a hypervisor interfering with these values. We will also touch upon the impact and potential for entropy loss from interrupt event correlation across multiple VMs sharing hardware. I don’t think we need to address containers, there’s a good post describing those effects here.
First, let’s talk about the LRNG’s entropy estimation ‘heuristic’, this becomes important when we consider the problem in light of NIST requirements for seeding pseudo random number generators (PRNGs) – The LRNG consists of three pools, the primary, secondary and urandom pools. Concretely, the term ‘pool’ refers to m-bit arrays sized at 4096, 1024 and 1024 bits respectively. Entropy is ‘mixed’ into the primary and sometimes to the secondary pool. Based on this, an entropy count for each of the pools is incremented. It should be clear that the maximal entropy possible for the primary pool is 4096 bits. To expand on intuition provided earlier, If we think of each bit in a 4096 bit string as being equally likely (i.e., each bit is uniformly generated), then each of the 2^4096 variants of this string is equally likely giving us a maximal uncertainty, or ‘entropy’, of 4096 bits for this string. When we say that a string has 4096 ‘bits’ of entropy, we mean to say there is a hidden string that can take on 2^4096 distinct values and your chance of guessing the actual value is 1 in 2^4096 . Importantly, quantifying entropy requires that (i) we can estimate a distribution on the string (as we did above by assuming each bit in the string is uniformly generated), (ii) we choose an estimate of entropy such as so called Shannon entropy, or alternatively, a more conservative estimate favored by NIST, the ‘min’ entropy.
The next thing to consider is how do we estimate or model a distribution on the events used to generate random bits in this string. In the case of the toy example above where we consider parity of interrupt times, a natural model may be to use the uniformity assumption, i.e., it’s just as likely that a timestamp has even or odd parity. But the LRNG doesn’t consider uncertainty in the parity, rather the random variable considered is a 32 bit word representing time of an interrupt in millisecs since system boot along with a time value provided by the ‘high resolution’ CPU timer, instances of which are mixed into the entropy pools along with auxiliary data. What is a reasonable distribution for this variable (actually, a more important question is what is the distribution of the **low order bits** of this variable), and is it something that exhibits short and long range uncertainty? Hard to say, it would depend on a number of factors including the type of device and it’s usage pattern – it’s a little deceptive to think of the ‘exact’ entropy of a random variable of this nature – this is something that can’t truly be known owing to its inherent uncertainty. Since we lack a priori knowledge of its distribution, it’s something that must be estimated by collecting a sufficiently large sample of data and fitting a distribution or using related min entropy estimation methods (‘binning’, collision estimates etc.). Based on this, the GPR2006 authors estimate about 1.03 bits of entropy per interrupt event based on a collection of 140K events (though the exact entropy estimate used is unclear). Later, we will look at other studies that sample block device I/O events for the purpose of estimating the entropy of these events in a VM running on a variety of hypervisors.
From a concrete standpoint, the LRNG does not use min entropy estimation, rather, the estimation used is a heuristic based on taking the logarithm of inter-arrival times of interrupts along with their ‘finite derivatives’. The details are not important, the point is that the heuristic potentially runs afoul of NIST recommendations which require min entropy estimates of PRNG seeds. On the bright side, GPR2006 and other studies allude to the fact that the RNG’s estimation heuristic is likely quite conservative. Other than entropy estimation, a couple of other things to consider are (i) periodicity, structural and algorithmic aspects of the LRNG state and entropy extraction functions and comparison to other NIST functions for generating pseudo random sequences (ii) initial seeding and use of the generators, especially during critical periods following system boot / reset, along with NIST seeding requirements vis a vis the ‘instantiation strength’ (Section 12.1) of generators.
First, lets consider the structural and algorithmic aspects of the LRNG. Though the LRNG is known to provide good random data for cryptographic applications, a head to head comparison with NIST PRNGs (section 12.1) is not truly possible, and it’s difficult to impute suitability of the LRNG for ciphering functions by looking at comparable guidance for the NIST PRNGs. For the non blocking urandom pool in particular, we can say that (i) it has no direct interaction with noise sources (ii) has a ‘mixing function that incorporates a linear feedback shift register (LFSR) generating elements in field extensions (we describe this later) (iii) uses SHA-1 for output extraction from its internal pool. This makes it structurally somewhat different from the NIST SP 800 90A generators as well as some of the other Linux generators such as the ‘jitterPRNG’ which is based on variation in execution times for a fixed set of CPU instructions.
We gain a coarse intuition for thinking of the periods of deterministic (pseudo random) generators by considering their outputs as elements in large finite fields. Specifically, consider a field of order 
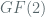

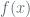
![\mathbb{Z}[X] / f(x)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5BX%5D+%2F+%C2%A0f%28x%29&bg=ffffff&fg=516064&s=0&c=20201002)




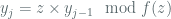
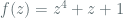

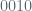

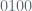










Clearly the period for this method is 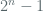


Finally we consider the effects of virtualization on the collection and entropy along, with the initial seeding of the generator. On the subject of seeding, we cite guidance from Stephan Muller in a proposal for a new generator motivated by a study on the effects of virtualization on entropy collection. In this proposal, Muller states that – “[the] DRBG is seeded with full security strength of 256 bits during the first steps of the initramfs time after about 1.3 seconds after boot. That measurement was taken within a virtual machine with very few devices attached where the legacy /dev/random implementation initializes the nonblocking_pool after 30 seconds or more since boot with 128 bits of entropy”.
It should be explicitly said that the term ‘DRBG’ above refers not to the existing LRNG, but to the entropy collection mechanism for a proposed kernel generator based on well studied NIST SP 800 90A algorithms (but excluding the NIST ‘Dual-EC DRBG’ algorithm). Whereas the proposed generator collects entropy quite rapidly, based on this study, rate of collection is much lower for the LRNG which, strictly speaking, does not have sufficient entropy for applications requiring more than 128 bits of entropy (eg. AES 256 bit key generation, secret key generation on the p384 elliptic curve etc. ) at 30 seconds past boot. This situation can be alleviated in some cases by configuring systems to persist a seed at system shutdown that is re-read during boot (and this requires that the seed is kept secret), but persisting a seed is obviously not an option with strategies for continuous ‘repaving’ of systems.
When thinking about virtualization and the accumulation of entropy, we note that hypervisors typically broker access to hardware, and in some cases, abstract underlying hardware to VMs. Brokering of access is typically done either by serializing access requests from multiple guests to a hardware resource, or in some cases, by exclusively assigning access to a single VM. Exclusive or serialized access to hardware is desirable from a cryptographic standpoint since it implies that two guests on the same hardware cannot arrive at a shared view of the state and events generated by this hardware. This is obviously a good thing since from the definition of entropy, any sharing and reuse of timing information among more than one party has the effect of negating all the uncertainty in this information. This BSI study (also authored by Muller) hypothetically poses scenarios where errors in estimation of entropy through the estimation heuristic may occur. The thinking here is that this can arise due to delays added by a hypervisor’s handling of hardware timing events. Shortly, I’ll cite some results from this study around actual entropy measurements obtained by sampling numerous block device events on a variety of hypervisors.
In theory, a hypervisor can emulate most devices, such as a block I/O device with spinning platters (so called ‘rotational’ devices), by converting a VM’s request to such a device to another type of request (eg. a network call) that bears no similarity with the original hardware. It’s important to note this – the kernel does not, for example, consider events generated from flash storage for entropy collection owing to their higher predictability – whereas this is a safeguard that could be obviated by a hypervisor that provides block device emulation of flash storage or a ramdisk. In other cases, the hypervisor may return data corresponding to a block I/O request by retrieving it from a cache rather than accessing the device, a fact that may materially impact uncertainty of related timing events.
The BSI study referenced above provides concrete numbers around the statistical properties of entropy sources in a virtual environment. A quick recap of some of the results for block I/O devices are summarized below:
Fig. 11 in the reference shows 0.43 bits of entropy in the ‘jiffies delta’, i.e., the difference between successive block I/O interrupt time stamps (measured in millisecs) based on 100K samples for a block I/O device on the KVM hypervisor without buffer caching. This figure shows that the majority of the jiffies deltas are either zero or one therefore containing a high degree of predictability. Fig 14, on the other hand, assigns a Shannon entropy of 16 bits to the 22 low bits of the high-resolution timestamp delta, showing that the low bits of the differences of high resolution timestamps provide the bulk of entropy for block devices. The author also points out that this is greater than the max. assignable value of 11 bits of entropy to a single delta by the estimation heuristic, which supports the statement that the latter method is indeed a conservative estimate for a virtualized environment of this type. Remarkably, figure 19 in this reference shows that the low 22 bits of the block I/O high resolution timestamp difference with hypervisor caching enabled contain about 15 bits of Shannon entropy, which is almost the same as the entropy conveyed in the previous statistic with caching disabled. This implies that buffer caching of data by the KVM hypervisor does not seem to alter inherent uncertainty of this phenomenon. Figures 23 and 28 show similar distributions for block device I/O on Oracle’s VirtualBox with Shannon entropy of the low 22 bits at 13.7 and 14.95 bits respectively for buffer caching disabled vs. enabled scenarios where caching in this case has slightly increased the uncertainty of the events. The Block I/O experiments with caching enabled do not, however, discuss the level to which device reads actually result in cache hits which has material impact on access rates to the hardware. Similarly, fig. 32 shows 15.12 bits of entropy per event on a Microsoft hypervisor, whereas fig. 39 measures 13.61 bits of Shannon entropy per delta on VMWare ESX. Another point I should make is that with this study, the experiments measure timing on a single VM, they do not look at possible correlation of timestamp events on many VMs (for eg., two VMs on shared hardware requesting access to the same block in near simultaneity) – though theoretically, serialized access to the hardware will likely result in different timestamp values for the access.
In concluding, we’ve gone over the basics of entropy measurement and collection in the LRNG, and started a discussion on the effects of virtualization on timing events that provide the raw uncertainty for this process. Future work could include (i) a more detailed discussion of the LRNG mixing function (ii) more analysis on measurements of initial seed entropy of the non blocking urandom pool immediately after system boot. Based on my current understanding, this pool does not wait for sufficient entropy accumulation before transferring bits to calling applications, thereby violating NIST requirements around the entropy of seeds vis a vis the ‘instantiation strength’ of a PRNG (In my view this is the main issue with urandom rather than its periodicity) (iii) more analysis on the impact of virtualization on timing events not related to block device access (iv) my memory is hazy on this point, but I recall that RedHat may have obtained FIPS certification for a kernel RNG, it may be worthwhile to look into this. It was almost certainly not the LRNG, but another generator based on NIST SP 800 90A deterministic algorithms and NIST 800 90B entropy tests.
“for foundational discoveries and inventions that enable machine learning with artificial neural networks” – Swedish Academy
The 2024 Nobel Prize in Physics recognizes two researchers for their impact on machine learning. As stated by the Swedish Academy, the award recognizes the contributions of John Hopfield and Geoffrey Hinton for application of “tools from physics to develop methods that are the foundation of today’s powerful machine learning”. This post aims to provide background around the award of the 2024 prize to Hopfield and Hinton for their pioneering work, and to draw the connection between the dynamical nature of neural networks and ensembles of energetic particles in statistical physics. There’s a body of work, going back to the 1980’s, around applying equilibrium statistical mechanics to modeling cognitive processes in the brain. This work from the 80’s is prefaced by some prior developments – Hodgkin and Huxley’s potentiation model of the squid giant axon, the McCulloch–Pitts Neuron, Rosenblatt’s Perceptron model, and the gradient descent based Hopfield network, a recurrent neural network for modeling associative or “content addressable” memory. An elaboration of these concepts from a thermodynamic viewpoint is the so called Boltzmann Machine, an augmented Hopfield model with Boltzmann sampling that exhibits dynamical behavior akin to Simulated Annealing.
Framework for Neural Attention: Energetic Interpretation of the Alignment Model (Bahdanau, Cho, Bengio)
Even as modern transformer architectures seem removed from the models described later and cited by the Academy in its press release, its pertinent to note the first descriptions of neural attention by Bahdanau, Cho and Bengio “Neural Machine Translation by Jointly Learning to Align and Translate” (BCB2015). Here, the mechanism is described in terms of “the probability 



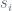
Ising Model
As we consider the work mentioned in the committee’s award, we’ll start with the Ising model of ferromagnetism – The setting for this model is a large lattice 


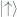



Returning to the Ising model, an electrostatic interaction or “coupling” term 
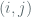
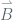
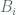


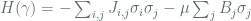
where 
Assuming particles are at thermal equilibrium with a heat bath (the lattice itself) at temperature 
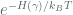
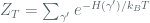
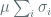
Hopfield Network (John Hopfield)
The Ising model associates a random variable at each lattice point with an intrinsic spin, that is, an angular momentum degree of freedom 
![[S_{i},S_{j}]= i \hbar \varepsilon_{ijk} S_{k}](https://s0.wp.com/latex.php?latex=%5BS_%7Bi%7D%2CS_%7Bj%7D%5D%3D+i++%5Chbar+%5Cvarepsilon_%7Bijk%7D+S_%7Bk%7D&bg=ffffff&fg=516064&s=0&c=20201002)
To elaborate further, we consider synchronous neurons where activity of the network is examined at discrete time intervals 
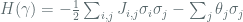
where 
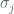

Dynamic initialization of the network is achieved by setting input units to a desired start pattern – this may be some partial representation of content that the network is designed to reconstruct or “retrieve” as part of its energy minimizing update process. We consider the dynamical landscape of the network as an “energy” landscape, where Lyapunov Energy Function is plotted as a function of the global state, and retrieval states of the system correspond to minima located within basins of attraction in this landscape. Hopfield showed that attractors in the system are stable rather than choatic, so convergence is usually assured.
Boltzmann Machine (Geoffrey Hinton and others)
The Boltzmann machine can be described as a Hopfield network (with hidden layers) that incorporates stochastic update of units. Rather than the Hopfield network that learns the exact form of the learned output, the Boltzmann machine learns distributions over desired outputs. Another waying stating this it is that the network learns approximations of the output. These characteristics make the network generative in the sense that it’s able to create outputs that are unique, outputs that have never been seen or generated before. The energy for the network is as described by the Lyapunov function above, but the stochastic update process introduces the notion of an artificial non zero temperature 

(i.e. 
The probability that the unit 


Coupling terms in the Lyapunov function are chosen so that energies of global network states (or “vectors”) represent the “cost” of these states – as such, stochastic search dynamics for the machine will evade inconsistent local extrema while searching for a low energy vector corresponding to the machine’s output. As alluded, this construction destabilizes poor local minima since the search is able to “jump” over energy barriers confining these minima.
The Boltzmann model introduces simulated annealing as a search optimization strategy. Here, we scale parameters by an artificial temperature T (multiplied by the Boltzmann constant 
In concluding, it’s interesting to note recent uptake of statistical mechanics and related tools within inter-disciplinary efforts to model brain function. This work, spanning fields such as applied physics, neuroscience and electrical engineering, grapples with a range of interesting problems.
Segue on the Onsager Solution to the Ising Porblem:
An exact solution of the 2-D Ising problem on square lattices was provided by Onsager, widely considered a landmark result in statistical mechanics since, among other things, it captures the ability to model phase transitions in the theory. The solution predicts logarithmic divergences in the specific heat of the system at the critical “Curie” temperature along with an expression for it’s long range order. The classic solution leverages a transfer matrix method for evaluating the 2-D partition function – details are beyond the scope of this article, the reader is referred to Bhattarcahrjee and Khare’s retrospective on the subject. Yet another class of solution to the 2-D Ising problem starts by considering a quantum partition function for the 1-D quantum Ising system as an “imaginary time” path integral, and then noting equivalence of the resulting expression to a partition function for the classical 2-D system evaluated as a transfer matrix. Leo Kadanoff, for example, motivates the blueprint for such a program by noting that every quantum mechanical trace [sum over histories] can be converted into a one-dimensional statistical mechanics problem and vice versa.
