The following is a post on the concrete security of symmetric encryption, focused primarily on the work of Bellare, Desai, Jokipii and Rogaway [BDJR1997], which builds on prior work of Goldwasser and Micali on the notions of semantic security and ciphertext indistinguishability in a complexity theoretic setting. The [BDJR1997] work views these concepts in the context of symmetric encryption and presents the additional notions of left-or-right and real-or-random indistinguishability followed by what are in all but a single case security preserving reductions between the notions in the CPA and CCA sense.
Following this [BDJR1997] provides a concrete security analysis of some of the prevalent modes of operation, of interest to us here are the counter modes. There are two such modes discussed, the 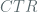 and
and 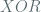 schemes, where the former is stateful counter mode whereas the latter is randomized counter mode in which the nonce
schemes, where the former is stateful counter mode whereas the latter is randomized counter mode in which the nonce  is sampled uniformly from the set of all
is sampled uniformly from the set of all  bit strings (where is the block size of the underlying PRF in bits). Also since we are talking about counter modes that do not require the block cipher decryption operation, we’re strictly not required to consider pseudo-random permutations and treat the underlying cipher (AES) as a PRF, thereby relating the advantage of an adversary attacking the mode of operation to the PRF insecurity (the advantage of attacking AES as a PRF).
bit strings (where is the block size of the underlying PRF in bits). Also since we are talking about counter modes that do not require the block cipher decryption operation, we’re strictly not required to consider pseudo-random permutations and treat the underlying cipher (AES) as a PRF, thereby relating the advantage of an adversary attacking the mode of operation to the PRF insecurity (the advantage of attacking AES as a PRF).
The theorem of interest from the paper for AES counter modes we consider is the following (Theorem 11), related to the scheme (randomized counter mode):
![\textbf{Adv}^{lor-cpa}_{XOR[F]}(\dot,t,q_{e},\mu_{e}) \leq 2 \cdot \textbf{Adv}^{prf}_F + \frac{\mu_{e} \cdot (q_{e} -1)} { L \cdot 2^{l}}](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BF%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29+%5Cleq+2+%5Ccdot+%5Ctextbf%7BAdv%7D%5E%7Bprf%7D_F+%2B+%5Cfrac%7B%5Cmu_%7Be%7D+%5Ccdot+%28q_%7Be%7D+-1%29%7D+%7B+L+%5Ccdot+2%5E%7Bl%7D%7D&bg=ffffff&fg=516064&s=0&c=20201002)
In the above expression, ![\textbf{Adv}^{lor-cpa}_{XOR[F]}(\dot,t,q_{e},\mu_{e})](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BF%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29&bg=ffffff&fg=516064&s=0&c=20201002) is the advantage of an adversary attacking the scheme in the left-or-right distinguishing game with
is the advantage of an adversary attacking the scheme in the left-or-right distinguishing game with  as PRF,
as PRF, 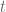 relates to the running time of the adversary,
relates to the running time of the adversary,  relates to the total ciphertext seen by the adversary and
relates to the total ciphertext seen by the adversary and  denotes the total number of oracle queries. Moreover,
denotes the total number of oracle queries. Moreover, 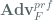 , the PRF insecurity, is the advantage of a PRF adversary attacking (AES, in our case), is the total ciphertext seen by the adversary, denotes the total number of queries to the LOR oracle, is the size of the PRF input in bits (128 in the case of AES) and
, the PRF insecurity, is the advantage of a PRF adversary attacking (AES, in our case), is the total ciphertext seen by the adversary, denotes the total number of queries to the LOR oracle, is the size of the PRF input in bits (128 in the case of AES) and 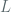 is the PRF output length in bits. Under the AES assumption, we take to be a negligible quantity and seek to to understand the advantage conferred to the
is the PRF output length in bits. Under the AES assumption, we take to be a negligible quantity and seek to to understand the advantage conferred to the ![XOR[F]](https://s0.wp.com/latex.php?latex=XOR%5BF%5D&bg=ffffff&fg=516064&s=0&c=20201002) adversary by the term
adversary by the term 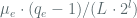 . Since we expect the PRF input to be appropriately padded to the block size, we take to also mean the block size of the PRF in bits. While details around the proof of theorem 11 are left to the reader, at a high level, it employs a reduction from the pseudo-randomness of the PRF to the security of the mode of operation, where an adversary attacking with advantage greater than is used to build a distinguisher that attacks the PRF with advantage exceeding , thereby contradicting the assumption of as a psuedo-random function (Concretely, the distinguisher
. Since we expect the PRF input to be appropriately padded to the block size, we take to also mean the block size of the PRF in bits. While details around the proof of theorem 11 are left to the reader, at a high level, it employs a reduction from the pseudo-randomness of the PRF to the security of the mode of operation, where an adversary attacking with advantage greater than is used to build a distinguisher that attacks the PRF with advantage exceeding , thereby contradicting the assumption of as a psuedo-random function (Concretely, the distinguisher 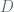 which is attacking and is able to implement the scheme simulates the LOR-CPA oracle for the adversary
which is attacking and is able to implement the scheme simulates the LOR-CPA oracle for the adversary  . If is able to successfully determine whether it is in the ‘left’ or ‘right’ game, the distinguisher assumes that is psuedo-random, otherwise it guesses that is a random function). The term can be thought of as a bound on the likelihood of an overlap of nonces (or an overlap of counters) across the distinct oracle queries in the distinguishing game – taking
. If is able to successfully determine whether it is in the ‘left’ or ‘right’ game, the distinguisher assumes that is psuedo-random, otherwise it guesses that is a random function). The term can be thought of as a bound on the likelihood of an overlap of nonces (or an overlap of counters) across the distinct oracle queries in the distinguishing game – taking 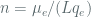 to be the average number of blocks per query, this term bounds the likelihood that
to be the average number of blocks per query, this term bounds the likelihood that  for any two nonces
for any two nonces 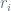 and
and  used to answer a pair of distinct oracle queries (where we treat and as positive integers). This proof, which is in the complexity theoretic setting, also leverages lemma 10 which provides an upper bound on the advantage of an adversary attacking the ideal scheme with a random function
used to answer a pair of distinct oracle queries (where we treat and as positive integers). This proof, which is in the complexity theoretic setting, also leverages lemma 10 which provides an upper bound on the advantage of an adversary attacking the ideal scheme with a random function  rather than the pseudo-random . We re-state lemma 10 below:
rather than the pseudo-random . We re-state lemma 10 below:
![\textbf{Adv}^{lor-cpa}_{XOR[R]}(\dot,t,q_{e},\mu_{e}) \leq \frac{\mu_{e} \cdot (q_{e} -1)} { L \cdot 2^{l}}](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BR%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29+%5Cleq%C2%A0+%5Cfrac%7B%5Cmu_%7Be%7D+%5Ccdot+%28q_%7Be%7D+-1%29%7D+%7B+L+%5Ccdot+2%5E%7Bl%7D%7D&bg=ffffff&fg=516064&s=0&c=20201002)
Where ![\textbf{Adv}^{lor-cpa}_{XOR[R]}(\dot,t,q_{e},\mu_{e})](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BR%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29&bg=ffffff&fg=516064&s=0&c=20201002) is the adversary’s advantage in attacking
is the adversary’s advantage in attacking ![XOR[R]](https://s0.wp.com/latex.php?latex=XOR%5BR%5D&bg=ffffff&fg=516064&s=0&c=20201002) .
.
Assuming to be negligible ( ) and setting as the number of blocks per oracle query, we can restate theorem 11 as:
) and setting as the number of blocks per oracle query, we can restate theorem 11 as:
![\textbf{Adv}^{lor-cpa}_{XOR[F]}(\dot,t,q_{e},\mu_{e}) \leq 2 \cdot \epsilon + \omega](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BAdv%7D%5E%7Blor-cpa%7D_%7BXOR%5BF%5D%7D%28%5Cdot%2Ct%2Cq_%7Be%7D%2C%5Cmu_%7Be%7D%29+%5Cleq+2+%5Ccdot+%5Cepsilon+%2B+%5Comega&bg=ffffff&fg=516064&s=0&c=20201002)
where  . Theorem 11 therefore states that so long as the underlying PRF is secure, the scheme is secure and the best that an adversary can do to break the scheme in the LOR-CPA sense is the so called “birthday attack” where the advantage exhibits a quadratic dependence on the number of queries.
. Theorem 11 therefore states that so long as the underlying PRF is secure, the scheme is secure and the best that an adversary can do to break the scheme in the LOR-CPA sense is the so called “birthday attack” where the advantage exhibits a quadratic dependence on the number of queries.
An Example
We now use the bounds derived above to get a sense of the advantage for an AES “randomized” counter-mode. In this case we set 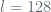 and assume
and assume  blocks per query. Importantly, we define the nonce
blocks per query. Importantly, we define the nonce  as
as  . If we wish to confine the adversary’s advantage to
. If we wish to confine the adversary’s advantage to  , what is the maximum number of oracle queries that limits the advantage at or below ? Putting the numbers into our expression for
, what is the maximum number of oracle queries that limits the advantage at or below ? Putting the numbers into our expression for  (above), we see that:
(above), we see that:
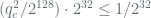


Therefore, in our example, to confine the LOR-CPA advantage below , it becomes necessary to rotate the encryption key prior to encryption queries (where each query consists of blocks, the reader may also refer to similar analysis around the “counter-mode theorem” here).
On the other hand, limiting the distinguishing advantage to  implies
implies  where once again, each query consists of blocks (or
where once again, each query consists of blocks (or  bytes).
bytes).
Encrypting Large Volumes
We now turn the discussion to requirements around rotating keys in scenarios where potentially large volumes of data at rest are encrypted – while other sites such as the Kubernetes’ encrypting data at rest page attempt to provide such guidance by providing bounds on the amount of data encrypted with a fixed key, they fail to explicitly do so from the standpoint of the distinguishing arguments and privacy / forgery bounds presented in [BDJR1997], whereas this post seeks to motivate limits on key usage from this viewpoint (later on, however, we’ll consider other factors around limiting key usage and lifespan independent of the concrete analysis). The Kubernetes page, for instance, prescribes a limit of 200K ( ) “writes” for a given key with AES-256 GCM and random nonces, but omits guidance for limits on the total number of blocks ciphered with a given key, a critical factor for determining privacy bounds.
) “writes” for a given key with AES-256 GCM and random nonces, but omits guidance for limits on the total number of blocks ciphered with a given key, a critical factor for determining privacy bounds.
To recap, in order to confine the adversary’s LOR-CPA distinguishing advantage below where the nonce is defined as , the analysis presented above puts a limit on the maximum number of blocks encrypted with a fixed key at 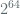 which corresponds to
which corresponds to 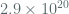 bytes (or 256 exbibytes). On the other hand, to confine the advantage below requires rotating the key before
bytes (or 256 exbibytes). On the other hand, to confine the advantage below requires rotating the key before  block encryptions under a fixed key (or 4 pebibytes. Also, as is typical in the complexity theoretic setting we take the PRF insecurity to be negligible).
block encryptions under a fixed key (or 4 pebibytes. Also, as is typical in the complexity theoretic setting we take the PRF insecurity to be negligible).
Limitations and Ambiguities in the GCM Spec.
NIST SP 800-38D limits the message size for a single GCM message at  bits (about 64 GiB) – no explicit analysis around this number in the vein of the [BDJR1997] distinguishing bounds are provided in the NIST publication. We surmise that stated limits most likely arise from (i) the fact that this is something that would be necessitated for usage patterns that use a 96 bit IV since the counter space in this construction is limited to after which the counter would wrap around and return to its initial value (also refer to later section that discusses “nonce counter-modes”) and though this is a less likely rationale (ii) the fact that GCM is vulnerable to hash key recovery and authentication tag forgery for short tags. Moreover, it has been recognized that there are number of ambiguous statements in the GCM spec around max invocations of the authenticated encryption function, to wit the following statement that “the total number of invocations of the authenticated encryption function shall not exceed , including all IV lengths and all instances of the authenticated encryption function with the given key”. Since the authenticated encryption function is used for both encryption and decryption purposes, it seems unclear whether this guidance seeks to limit the total amount of data encrypted (for all IV lengths) with a fixed key, or whether it truly seeks to limit the total number of and encryption and decryption operations for a given key. The following statement is an attempt at clarifying the above guidance by Philip Rogaway who relates an interpretation of this statement by David McGrew from personal communications (2/2011) as something implying that “the total number of invocations of the authenticated encryption function shall not exceed , including [invocations with] all IV lengths and all instance[s] of the authenticated encryption function with the given key.”
bits (about 64 GiB) – no explicit analysis around this number in the vein of the [BDJR1997] distinguishing bounds are provided in the NIST publication. We surmise that stated limits most likely arise from (i) the fact that this is something that would be necessitated for usage patterns that use a 96 bit IV since the counter space in this construction is limited to after which the counter would wrap around and return to its initial value (also refer to later section that discusses “nonce counter-modes”) and though this is a less likely rationale (ii) the fact that GCM is vulnerable to hash key recovery and authentication tag forgery for short tags. Moreover, it has been recognized that there are number of ambiguous statements in the GCM spec around max invocations of the authenticated encryption function, to wit the following statement that “the total number of invocations of the authenticated encryption function shall not exceed , including all IV lengths and all instances of the authenticated encryption function with the given key”. Since the authenticated encryption function is used for both encryption and decryption purposes, it seems unclear whether this guidance seeks to limit the total amount of data encrypted (for all IV lengths) with a fixed key, or whether it truly seeks to limit the total number of and encryption and decryption operations for a given key. The following statement is an attempt at clarifying the above guidance by Philip Rogaway who relates an interpretation of this statement by David McGrew from personal communications (2/2011) as something implying that “the total number of invocations of the authenticated encryption function shall not exceed , including [invocations with] all IV lengths and all instance[s] of the authenticated encryption function with the given key.”
Guidance on CCM Parameters
As an alternative to GCM, CCM authenticated encryption mode could be considered for encrypting larger volumes of data owing to larger specified privacy bonds (that we will discuss below). Unlike GCM, however, CCM does not offer the ability to compute the MAC in parallel, however, we do not view this as a concern in an offline encryption / decryption scenario. Also, CCM is not on-line in the sense that the length of the message must be known beforehand. On the other hand CCM, like GCM, is a NIST approved mode of operation which is of particular benefit in environments that require a high level of review. Moreover, CCM does not from a specification viewpoint have an explicit 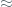 64 GiB limitation per message as is the case with GCM (along with the apparent 64GiB limit on total data encrypted with a given key) – in theory, these facts should give us greater flexibility around specifying maximal or average message sizes and viewing security bounds around key rotation in terms of the overall amount of data encrypted and the average size of each message based on [BDJR1997] type arguments.
64 GiB limitation per message as is the case with GCM (along with the apparent 64GiB limit on total data encrypted with a given key) – in theory, these facts should give us greater flexibility around specifying maximal or average message sizes and viewing security bounds around key rotation in terms of the overall amount of data encrypted and the average size of each message based on [BDJR1997] type arguments.
It is important to note that in the [BDJR1997] description of the scheme, the nonce, specified as 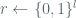 is drawn uniformly from the set of all bit strings where is the size of the block, whereas the CCM spec allows for a variable nonce size ranging from 56 to 104 bits. In other parts of the literature, the approach is often called “randomized counter-mode” whereas the approach of segmenting the block into two substrings, one for the nonce and another for the counter is sometimes referred to as “nonce counter-mode”.
is drawn uniformly from the set of all bit strings where is the size of the block, whereas the CCM spec allows for a variable nonce size ranging from 56 to 104 bits. In other parts of the literature, the approach is often called “randomized counter-mode” whereas the approach of segmenting the block into two substrings, one for the nonce and another for the counter is sometimes referred to as “nonce counter-mode”.
The length of the nonce is specified by the parameter ‘n’ and the spec allows for this to be 7, 8, 9, 10, 11, 12, or 13 bytes. The plaintext length in bytes, denoted ‘p’, is formatted as an octet string denoted Q in the first input block. The length of Q in bytes, is denoted q where q can take on the values 2, 3, 4, 5, 6, 7, 8 subject to the constraint n + q = 15. The value of q determines the max. size for a given message which is 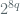 bytes. The byte length of the nonce n in turn determines the maximum number of CCM invocations for a given key, which is given by
bytes. The byte length of the nonce n in turn determines the maximum number of CCM invocations for a given key, which is given by  . The condition n + q = 15 therefore reflects a tradeoff between the max. CCM invocations for a given key and the max. size of the payload per invocation. If CCM is used, in this guidance, we specify the following CCM parameters –
. The condition n + q = 15 therefore reflects a tradeoff between the max. CCM invocations for a given key and the max. size of the payload per invocation. If CCM is used, in this guidance, we specify the following CCM parameters –
q = 5
This parameter allows message sizes upto  bytes or 1 tebibyte ( 1.1 terabytes). From the constraint n + q = 15, it follows that the size of the nonce in bytes is:
bytes or 1 tebibyte ( 1.1 terabytes). From the constraint n + q = 15, it follows that the size of the nonce in bytes is:
n = 10
Finally we specify the length of the tag in octets as:
t = 16
We recommend a key size of 256 bits.
Rationale
Why do we select the following parameters? The selection is primarily driven by the need for designing a method that will aid in ease of implementation while remaining secure. Though implementors will chunk inputs under the 1.1 TB limit owing to buffering limits (see later section on discussion on the OpenSSL CCM API), they are theoretically not required to do so with the specified parameters. Another goal for the specified parameters is to make the nonce space large – the rationale for this is that we cannot control how implementors will generate the nonces. The privacy analysis of CCM is based on the assumption of a nonce-respecting adversary that does not repeat nonces across invocations. In practice, however, since the nonce must be supplied by the user as input to the scheme, we are not entirely confident that users will be nonce-respecting. They may randomly sample nonces. Given this fact, we think it prudent to specify a larger nonce space to reduce the likelihood of collisions while limiting the number of distinct messages encrypted with a given key (but at the same time discourage the use of random nonces). Then, for illustration purposes, we’ll consider the overall privacy bounds for the parameters specified above by limiting the number of distinct messages encrypted under a given key to 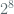 (albeit under the nonce-respecting assumption). If the freshness of nonces is not something that can be guaranteed by the implementation, then implementors may consider using the key just once to encrypt a single large data artifact with this method.
(albeit under the nonce-respecting assumption). If the freshness of nonces is not something that can be guaranteed by the implementation, then implementors may consider using the key just once to encrypt a single large data artifact with this method.
While we have thus far discussed limits on key usage from a concrete security standpoint, there are several reasons to rotate keys before such data limits are reached, significant among those reasons being leakage of all or parts of the key – fragmenting of data into smaller portions and generating distinct data encrypting keys per fragment limits the amount of information leaked in the event that a single key is compromised. While implementors should consider these facts and may refer to extant practice on this subject, for instance, here, we once more emphasize the primary goal of this exercise is to talk about actual limits arising from the concrete privacy bounds.
Returning to our parameters, the max limit on the number of block cipher calls for a given key is  , which is well under the stated limit of
, which is well under the stated limit of  invocations for the lifetime of a key stated in the spec. Moreover, it is typical practice to assign a so called “cryptoperiod” to limit exposure of data based on a number of risk factors, for more information, the reader to is referred to section 5 of NIST Special Publication 800-57 Part 1 Revision 4 Recommendation for Key Management Part 1. Considering the guidance above and shortening cryptoperiods should be considered as part of a broader enterprise security strategy around establishing good key hygiene – there has been significant movement on this subject with platform vendors actively seeking to reduce friction associated with key rotation through the use of automation, the reader is referred to the post The Three Rs of Enterprise Security: Rotate, Repave, and Repair for views on emerging industry practices.
invocations for the lifetime of a key stated in the spec. Moreover, it is typical practice to assign a so called “cryptoperiod” to limit exposure of data based on a number of risk factors, for more information, the reader to is referred to section 5 of NIST Special Publication 800-57 Part 1 Revision 4 Recommendation for Key Management Part 1. Considering the guidance above and shortening cryptoperiods should be considered as part of a broader enterprise security strategy around establishing good key hygiene – there has been significant movement on this subject with platform vendors actively seeking to reduce friction associated with key rotation through the use of automation, the reader is referred to the post The Three Rs of Enterprise Security: Rotate, Repave, and Repair for views on emerging industry practices.
Key Wrapping
As mentioned, there are compelling reasons to fragment data, encrypt, and then spread it across different physical volumes. In this case, it can be beneficial to locate the data encryption key near or along with the data being encrypted. For these scenarios, we recommend key wrapping of the data encrypting key with AES-256 GCM (refer to internal Pivotal standards for these ciphers). Ideally, the key encrypting key should be stored in an HSM. We do not currently advocate the use of key wrapping mechanisms in NIST Special Publication 800-38F “Recommendation for Block Cipher Modes of Operation: Methods for Key Wrapping”.
Appendix A: CCM Privacy Bounds
Here, we relay the concrete privacy bounds provided by Jakob Jonsson, which are stated as:
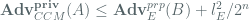
where is the advantage of a CCM attacker . This in turn is related to the advantage of an adversary
is the advantage of a CCM attacker . This in turn is related to the advantage of an adversary 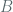 attacking the block cipher (AES)
attacking the block cipher (AES)  as a PRP (through the switching lemma) plus the birthday term
as a PRP (through the switching lemma) plus the birthday term  exhibiting quadratic dependence on the number of queries
exhibiting quadratic dependence on the number of queries  where
where 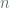 is the size of the block (128). Given that the standard mandates use of the PRP for no more than
is the size of the block (128). Given that the standard mandates use of the PRP for no more than  calls, the bounds yield a maximal advantage of 0.016 in addition to the PRP insecurity for a given key. Our earlier example (refer to the section entitled “Rationale”) limiting the number of distinct calls at with a maximal message size of
calls, the bounds yield a maximal advantage of 0.016 in addition to the PRP insecurity for a given key. Our earlier example (refer to the section entitled “Rationale”) limiting the number of distinct calls at with a maximal message size of  bytes, on the other hand, yields the much smaller advantage
bytes, on the other hand, yields the much smaller advantage  (plus the PRP insecurity).
(plus the PRP insecurity).
