‘Entropy’, in the context of the Linux Random Number Generator (‘LRNG’), is an accretional quantity arising the uncertainty of hardware generated interrupt time stamps. If you’re already familiar with the mechanism, bear with me as I provide some intuition – consider timestamp parity and think of the kernel appending 0 to a stored register value if the millisec counter on an interrupt timestamp is even parity, or 1 if it’s odd, and then generating a string of random bits this way after witnessing many interrupts. The string of resulting bits can then be read out of the register for applications that require randomness, at which point the value is reset to zero. If we admit that even parity on timestamps is as likely as odd, it’s clear that the uncertainty (i.e., the entropy) in bitstrings from this construction is a function of the length of the strings : The greater the number of observed interrupts -> the longer the string -> the higher the entropy. Here is a simple illustration – assume that I create a 3 bit random string by observing the parity of three successive interrupt time values (measured in milliseconds since system boot). If these time values are 


The LRNG does not actually generate random bits this way (that is, by concatenating interrupt millisec time values modulo 2). Roughly, the actual method is based on uncertainty in interrupt times represented as ‘jiffies’, 32 bit words representing time of an interrupt in millisecs since system boot, along with a ‘high resolution’ time value obtained from the CPU. These values are ‘mixed’ into the entropy ‘pools’ from where an extraction function creates sequences of pseudo-random bits on demand. This is concretely described in Gutterman, Pinkas et. al’s description of breaks to backtracking resistance of the LRNG [GPR 2006]. The goal of this piece, however, is not to address weaknesses like the analytic breaks discussed above, it’s to try and address looming confusion on a couple of fronts including (i) general suitability of the LRNG pools, including the non blocking ‘urandom’ pool, for ciphering (ii) issues with the quality of randomness arising from virtualization, including arbitration and biasing of otherwise random processes by a hypervisor hosting multiple guest systems on shared hardware (iii) the conflation of virtualization and biasing effects mentioned above, with the effects of app containerization on a single VM.
Rather than expound on all the above, let’s address the suitability of the LRNG for ciphering, after which, perhaps we outline a discussion on real or perceived biasing of timestamp values due to a hypervisor interfering with these values. We will also touch upon the impact and potential for entropy loss from interrupt event correlation across multiple VMs sharing hardware. I don’t think we need to address containers, there’s a good post describing those effects here.
First, let’s talk about the LRNG’s entropy estimation ‘heuristic’, this becomes important when we consider the problem in light of NIST requirements for seeding pseudo random number generators (PRNGs) – The LRNG consists of three pools, the primary, secondary and urandom pools. Concretely, the term ‘pool’ refers to m-bit arrays sized at 4096, 1024 and 1024 bits respectively. Entropy is ‘mixed’ into the primary and sometimes to the secondary pool. Based on this, an entropy count for each of the pools is incremented. It should be clear that the maximal entropy possible for the primary pool is 4096 bits. To expand on intuition provided earlier, If we think of each bit in a 4096 bit string as being equally likely (i.e., each bit is uniformly generated), then each of the 2^4096 variants of this string is equally likely giving us a maximal uncertainty, or ‘entropy’, of 4096 bits for this string. When we say that a string has 4096 ‘bits’ of entropy, we mean to say there is a hidden string that can take on 2^4096 distinct values and your chance of guessing the actual value is 1 in 2^4096 . Importantly, quantifying entropy requires that (i) we can estimate a distribution on the string (as we did above by assuming each bit in the string is uniformly generated), (ii) we choose an estimate of entropy such as so called Shannon entropy, or alternatively, a more conservative estimate favored by NIST, the ‘min’ entropy.
The next thing to consider is how do we estimate or model a distribution on the events used to generate random bits in this string. In the case of the toy example above where we consider parity of interrupt times, a natural model may be to use the uniformity assumption, i.e., it’s just as likely that a timestamp has even or odd parity. But the LRNG doesn’t consider uncertainty in the parity, rather the random variable considered is a 32 bit word representing time of an interrupt in millisecs since system boot along with a time value provided by the ‘high resolution’ CPU timer, instances of which are mixed into the entropy pools along with auxiliary data. What is a reasonable distribution for this variable (actually, a more important question is what is the distribution of the **low order bits** of this variable), and is it something that exhibits short and long range uncertainty? Hard to say, it would depend on a number of factors including the type of device and it’s usage pattern – it’s a little deceptive to think of the ‘exact’ entropy of a random variable of this nature – this is something that can’t truly be known owing to its inherent uncertainty. Since we lack a priori knowledge of its distribution, it’s something that must be estimated by collecting a sufficiently large sample of data and fitting a distribution or using related min entropy estimation methods (‘binning’, collision estimates etc.). Based on this, the GPR2006 authors estimate about 1.03 bits of entropy per interrupt event based on a collection of 140K events (though the exact entropy estimate used is unclear). Later, we will look at other studies that sample block device I/O events for the purpose of estimating the entropy of these events in a VM running on a variety of hypervisors.
From a concrete standpoint, the LRNG does not use min entropy estimation, rather, the estimation used is a heuristic based on taking the logarithm of inter-arrival times of interrupts along with their ‘finite derivatives’. The details are not important, the point is that the heuristic potentially runs afoul of NIST recommendations which require min entropy estimates of PRNG seeds. On the bright side, GPR2006 and other studies allude to the fact that the RNG’s estimation heuristic is likely quite conservative. Other than entropy estimation, a couple of other things to consider are (i) periodicity, structural and algorithmic aspects of the LRNG state and entropy extraction functions and comparison to other NIST functions for generating pseudo random sequences (ii) initial seeding and use of the generators, especially during critical periods following system boot / reset, along with NIST seeding requirements vis a vis the ‘instantiation strength’ (Section 12.1) of generators.
First, lets consider the structural and algorithmic aspects of the LRNG. Though the LRNG is known to provide good random data for cryptographic applications, a head to head comparison with NIST PRNGs (section 12.1) is not truly possible, and it’s difficult to impute suitability of the LRNG for ciphering functions by looking at comparable guidance for the NIST PRNGs. For the non blocking urandom pool in particular, we can say that (i) it has no direct interaction with noise sources (ii) has a ‘mixing function that incorporates a linear feedback shift register (LFSR) generating elements in field extensions (we describe this later) (iii) uses SHA-1 for output extraction from its internal pool. This makes it structurally somewhat different from the NIST SP 800 90A generators as well as some of the other Linux generators such as the ‘jitterPRNG’ which is based on variation in execution times for a fixed set of CPU instructions.
We gain a coarse intuition for thinking of the periods of deterministic (pseudo random) generators by considering their outputs as elements in large finite fields. Specifically, consider a field of order 
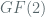

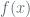
![\mathbb{Z}[X] / f(x)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5BX%5D+%2F+%C2%A0f%28x%29&bg=ffffff&fg=516064&s=0&c=20201002)




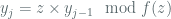
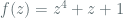

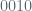

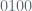










Clearly the period for this method is 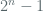


Finally we consider the effects of virtualization on the collection and entropy along, with the initial seeding of the generator. On the subject of seeding, we cite guidance from Stephan Muller in a proposal for a new generator motivated by a study on the effects of virtualization on entropy collection. In this proposal, Muller states that – “[the] DRBG is seeded with full security strength of 256 bits during the first steps of the initramfs time after about 1.3 seconds after boot. That measurement was taken within a virtual machine with very few devices attached where the legacy /dev/random implementation initializes the nonblocking_pool after 30 seconds or more since boot with 128 bits of entropy”.
It should be explicitly said that the term ‘DRBG’ above refers not to the existing LRNG, but to the entropy collection mechanism for a proposed kernel generator based on well studied NIST SP 800 90A algorithms (but excluding the NIST ‘Dual-EC DRBG’ algorithm). Whereas the proposed generator collects entropy quite rapidly, based on this study, rate of collection is much lower for the LRNG which, strictly speaking, does not have sufficient entropy for applications requiring more than 128 bits of entropy (eg. AES 256 bit key generation, secret key generation on the p384 elliptic curve etc. ) at 30 seconds past boot. This situation can be alleviated in some cases by configuring systems to persist a seed at system shutdown that is re-read during boot (and this requires that the seed is kept secret), but persisting a seed is obviously not an option with strategies for continuous ‘repaving’ of systems.
When thinking about virtualization and the accumulation of entropy, we note that hypervisors typically broker access to hardware, and in some cases, abstract underlying hardware to VMs. Brokering of access is typically done either by serializing access requests from multiple guests to a hardware resource, or in some cases, by exclusively assigning access to a single VM. Exclusive or serialized access to hardware is desirable from a cryptographic standpoint since it implies that two guests on the same hardware cannot arrive at a shared view of the state and events generated by this hardware. This is obviously a good thing since from the definition of entropy, any sharing and reuse of timing information among more than one party has the effect of negating all the uncertainty in this information. This BSI study (also authored by Muller) hypothetically poses scenarios where errors in estimation of entropy through the estimation heuristic may occur. The thinking here is that this can arise due to delays added by a hypervisor’s handling of hardware timing events. Shortly, I’ll cite some results from this study around actual entropy measurements obtained by sampling numerous block device events on a variety of hypervisors.
In theory, a hypervisor can emulate most devices, such as a block I/O device with spinning platters (so called ‘rotational’ devices), by converting a VM’s request to such a device to another type of request (eg. a network call) that bears no similarity with the original hardware. It’s important to note this – the kernel does not, for example, consider events generated from flash storage for entropy collection owing to their higher predictability – whereas this is a safeguard that could be obviated by a hypervisor that provides block device emulation of flash storage or a ramdisk. In other cases, the hypervisor may return data corresponding to a block I/O request by retrieving it from a cache rather than accessing the device, a fact that may materially impact uncertainty of related timing events.
The BSI study referenced above provides concrete numbers around the statistical properties of entropy sources in a virtual environment. A quick recap of some of the results for block I/O devices are summarized below:
Fig. 11 in the reference shows 0.43 bits of entropy in the ‘jiffies delta’, i.e., the difference between successive block I/O interrupt time stamps (measured in millisecs) based on 100K samples for a block I/O device on the KVM hypervisor without buffer caching. This figure shows that the majority of the jiffies deltas are either zero or one therefore containing a high degree of predictability. Fig 14, on the other hand, assigns a Shannon entropy of 16 bits to the 22 low bits of the high-resolution timestamp delta, showing that the low bits of the differences of high resolution timestamps provide the bulk of entropy for block devices. The author also points out that this is greater than the max. assignable value of 11 bits of entropy to a single delta by the estimation heuristic, which supports the statement that the latter method is indeed a conservative estimate for a virtualized environment of this type. Remarkably, figure 19 in this reference shows that the low 22 bits of the block I/O high resolution timestamp difference with hypervisor caching enabled contain about 15 bits of Shannon entropy, which is almost the same as the entropy conveyed in the previous statistic with caching disabled. This implies that buffer caching of data by the KVM hypervisor does not seem to alter inherent uncertainty of this phenomenon. Figures 23 and 28 show similar distributions for block device I/O on Oracle’s VirtualBox with Shannon entropy of the low 22 bits at 13.7 and 14.95 bits respectively for buffer caching disabled vs. enabled scenarios where caching in this case has slightly increased the uncertainty of the events. The Block I/O experiments with caching enabled do not, however, discuss the level to which device reads actually result in cache hits which has material impact on access rates to the hardware. Similarly, fig. 32 shows 15.12 bits of entropy per event on a Microsoft hypervisor, whereas fig. 39 measures 13.61 bits of Shannon entropy per delta on VMWare ESX. Another point I should make is that with this study, the experiments measure timing on a single VM, they do not look at possible correlation of timestamp events on many VMs (for eg., two VMs on shared hardware requesting access to the same block in near simultaneity) – though theoretically, serialized access to the hardware will likely result in different timestamp values for the access.
In concluding, we’ve gone over the basics of entropy measurement and collection in the LRNG, and started a discussion on the effects of virtualization on timing events that provide the raw uncertainty for this process. Future work could include (i) a more detailed discussion of the LRNG mixing function (ii) more analysis on measurements of initial seed entropy of the non blocking urandom pool immediately after system boot. Based on my current understanding, this pool does not wait for sufficient entropy accumulation before transferring bits to calling applications, thereby violating NIST requirements around the entropy of seeds vis a vis the ‘instantiation strength’ of a PRNG (In my view this is the main issue with urandom rather than its periodicity) (iii) more analysis on the impact of virtualization on timing events not related to block device access (iv) my memory is hazy on this point, but I recall that RedHat may have obtained FIPS certification for a kernel RNG, it may be worthwhile to look into this. It was almost certainly not the LRNG, but another generator based on NIST SP 800 90A deterministic algorithms and NIST 800 90B entropy tests.
